I have two data-frames :
df1 = pd.DataFrame({'Item_Description': ['SYD_SYDNEY AIRPORTS CORPORATION LIMITED-Aircraft Parking :Sep','SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep', 'SYD_SNP SECURITY SERVICES PTY LTD-Aircraft Security :Sep'
], 'Commodity_Code': ["", "", "",], })
df2 = pd.DataFrame({'Item': ['Turn Cost', 'Aircraft Security'
, 'Aircraft Parking'], 'Commodity_Code': [24101900, 92121700, 78141805,], })
I would like to fill in the Commodity_Code from df1 based on the item from df2 which is a part of a string in Item_Description (df1). For example: "Turn Cost" is a part of the string : "SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep" so the Commodity Code would be : 24101900
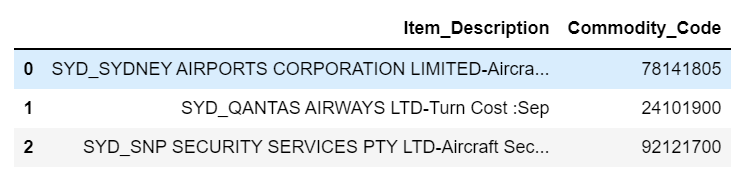
The expected result would be :
CodePudding user response:
First lets extract the Item into df1 then we can merge to get the commodity code.
#df1 = df1.drop('Commodity Code',axis=1) # you don't need an empty column..
pat = '|'.join(df2['Item'].values)
df1['Item'] = df1['Item_Description'].str.extract(f"({pat})")
Item_Description Item
0 SYD_SYDNEY AIRPORTS CORPORATION LIMITED-Aircra... Aircraft Parking
1 SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep Turn Cost
2 SYD_SNP SECURITY SERVICES PTY LTD-Aircraft Sec... Aircraft Security
final = pd.merge(df1,df2,on=['Item'],how='left')
print(final.drop('Item',axis=1))
Item_Description Commodity_Code
0 SYD_SYDNEY AIRPORTS CORPORATION LIMITED-Aircra... 78141805
1 SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep 24101900
2 SYD_SNP SECURITY SERVICES PTY LTD-Aircraft Sec... 92121700
CodePudding user response:
You can merge them in a cross join:
merged = df1.merge(df2, how='cross', suffixes=['_x', ''])
merged
| Item_Description | Commodity_Code_x | key | Item | Commodity_Code |
|---|---|---|---|---|
| SYD_SYDNEY AIRPORTS CORPORATION LIMITED-Aircraft Parking :Sep | 0 | Turn Cost | 24101900 | |
| SYD_SYDNEY AIRPORTS CORPORATION LIMITED-Aircraft Parking :Sep | 0 | Aircraft Security | 92121700 | |
| SYD_SYDNEY AIRPORTS CORPORATION LIMITED-Aircraft Parking :Sep | 0 | Aircraft Parking | 78141805 | |
| SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep | 0 | Turn Cost | 24101900 | |
| SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep | 0 | Aircraft Security | 92121700 | |
| SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep | 0 | Aircraft Parking | 78141805 | |
| SYD_SNP SECURITY SERVICES PTY LTD-Aircraft Security :Sep | 0 | Turn Cost | 24101900 | |
| SYD_SNP SECURITY SERVICES PTY LTD-Aircraft Security :Sep | 0 | Aircraft Security | 92121700 | |
| SYD_SNP SECURITY SERVICES PTY LTD-Aircraft Security :Sep | 0 | Aircraft Parking | 78141805 |
Filter where Item is a substring of Item Description:
merged[merged.apply(lambda x:x.Item_Description.__contains__(x.Item), axis=1)].drop(columns=['Commodity_Code_x', 'key'])
| Item_Description | Item | Commodity_Code |
|---|---|---|
| SYD_SYDNEY AIRPORTS CORPORATION LIMITED-Aircraft Parking :Sep | Aircraft Parking | 78141805 |
| SYD_QANTAS AIRWAYS LTD-Turn Cost :Sep | Turn Cost | 24101900 |
| SYD_SNP SECURITY SERVICES PTY LTD-Aircraft Security :Sep | Aircraft Security | 92121700 |
Or if you want it within df1:
df1 = merged[merged.apply(lambda x:x.Item_Description.__contains__(x.Item), axis=1)].drop(columns=['Commodity_Code_x', 'key', 'Item'])