This is an additional question related to: 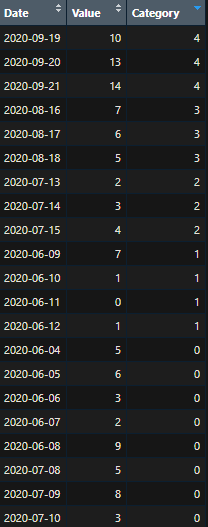
What I'm trying to subset, where the minimum date from the categories (colored accordingly) are in bold and the 3 days prior are highlighted for each:
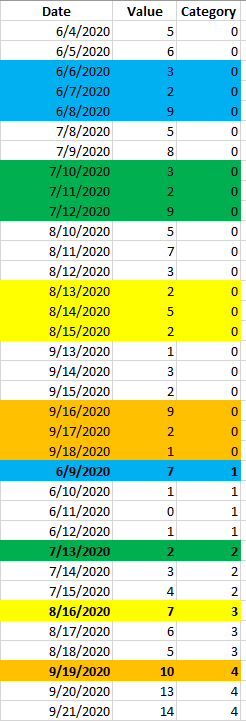
My goal end result:
Reprex:
library ("lubridate")
library("dplyr")
library("tidyr")
data <- data.frame(Date = c("2020-06-04",
"2020-06-05",
"2020-06-06",
"2020-06-07",
"2020-06-08",
"2020-07-08",
"2020-07-09",
"2020-07-10",
"2020-07-11",
"2020-07-12",
"2020-08-10",
"2020-08-11",
"2020-08-12",
"2020-08-13",
"2020-08-14",
"2020-08-15",
"2020-09-13",
"2020-09-14",
"2020-09-15",
"2020-09-16",
"2020-09-17",
"2020-09-18",
"2020-06-09",
"2020-06-10",
"2020-06-11",
"2020-06-12",
"2020-07-13",
"2020-07-14",
"2020-07-15",
"2020-08-16",
"2020-08-17",
"2020-08-18",
"2020-09-19",
"2020-09-20",
"2020-09-21"),
Value = c(5,6,3,2,9,
5,8,3,2,9,
5,7,3,2,5,
2,1,3,2,9,
2,1,7,1,0,
1,2,3,4,7,
6,5,10,13,14),
Category = c(0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0,
0,0,0,0,0,
0,0,1,1,1,
1,3,3,3,5,
5,5,7,7,7))
data$Date <- as.Date(data$Date)
View(data)
df <- bind_rows(
data %>%
group_by(Category) %>%
slice_min(Date) %>% #take the first date of each category
ungroup() %>%
mutate(Date=as.Date(Date)),
data %>%
group_by(Category) %>%
summarize(Date=seq(min(as.Date(Date))-3,by="day", length.out=3), .groups="keep", na.rm = TRUE) #goal is to take the previous 3 days from the first day of each category and keep all rows - right now, it's replacing them with NA values
)
head(df)
*edited to show categories might not be all nice and sequential
CodePudding user response:
firsts_3b <- data %>%
group_by(Category) %>%
slice_min(Date, n = 1) %>%
filter(Category != 0) %>%
summarize(Date = Date - (0:3)) %>%
pull(Date)
data %>%
arrange(Date) %>%
filter(Date %in% firsts_3b)
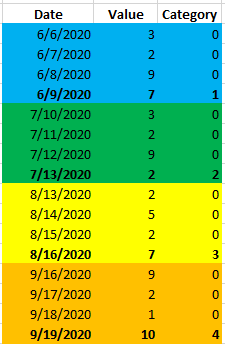
Result
Date Value Category
1 2020-06-06 3 0
2 2020-06-07 2 0
3 2020-06-08 9 0
4 2020-06-09 7 1
5 2020-07-10 3 0
6 2020-07-11 2 0
7 2020-07-12 9 0
8 2020-07-13 2 2
9 2020-08-13 2 0
10 2020-08-14 5 0
11 2020-08-15 2 0
12 2020-08-16 7 3
13 2020-09-16 9 0
14 2020-09-17 2 0
15 2020-09-18 1 0
16 2020-09-19 10 4