I have an excel, the data has two $ , when I read it using pandas, it will convert them to a very special text style.
import pandas as pd
df = pd.DataFrame({ 'Bid-Ask':['$185.25 - $186.10','$10.85 - $11.10','$14.70 - $15.10']})
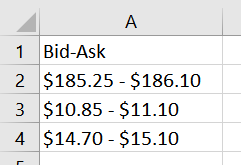
after pd.read_excel
df['Bid'] = df['Bid-Ask'].str.split('−').str[0]
above code doesn't work due to $ make my string into a special style text.the Split function doesn't work.
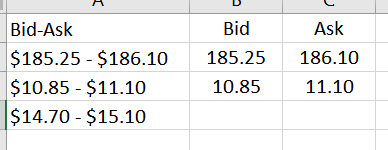
my expected result
CodePudding user response:
Do not split. Using str.extract is likely the most robust:
df[['Bid', 'Ask']] = df['Bid-Ask'].str.extract(r'(\d (?:\.\d )?)\D*(\d (?:\.\d )?)')
Output:
Bid-Ask Bid Ask
0 $185.25 - $186.10 185.25 186.10
1 $10.85 - $11.10 10.85 11.10
2 $14.70 - $15.10 14.70 15.10
CodePudding user response:
There is a non-breaking space (\xa0) in your string. That's why the split doesn't work.
I copied the strings (of your df) one by one into an Excel file and then imported it with pd.read_excel.
The column looks like this then:
repr(df['Bid-Ask'])
'0 $185.25\xa0- $186.10\n1 $10.85\xa0- $11.10\n2 $14.70\xa0- $15.10\nName: Bid-Ask, dtype: object'
Before splitting you can replace that and it'll work.
df['Bid-Ask'] = df['Bid-Ask'].astype('str').str.replace('\xa0',' ', regex=False)
df[['Bid', 'Ask']] = df['Bid-Ask'].str.replace('$','', regex=False).str.split('-',expand = True)
print(df)
Bid-Ask Bid Ask
0 $185.25 - $186.10 185.25 186.10
1 $10.85 - $11.10 10.85 11.10
2 $14.70 - $15.10 14.70 15.10
CodePudding user response:
You have to use the lambda function and apply the method together to split the column values into two and slice the value
df['Bid'] = df['Bid-Ask'].apply(lambda x: x.split('-')[0].strip()[1:])
df['Ask'] = df['Bid-Ask'].apply(lambda x: x.split('-')[1].strip()[1:])
output:
Bid-Ask Bid Ask
0 185.25− 186.10 185.25 186.1
1 10.85− 11.10 10.85 11.1
2 14.70− 15.10 14.70 15.1