I am using training an image classification model using the pre-trained mobile network. During training, I am seeing very high values (more than 70%) for Accuracy, Precision, Recall, and F1-score on both the training dataset and validation dataset.
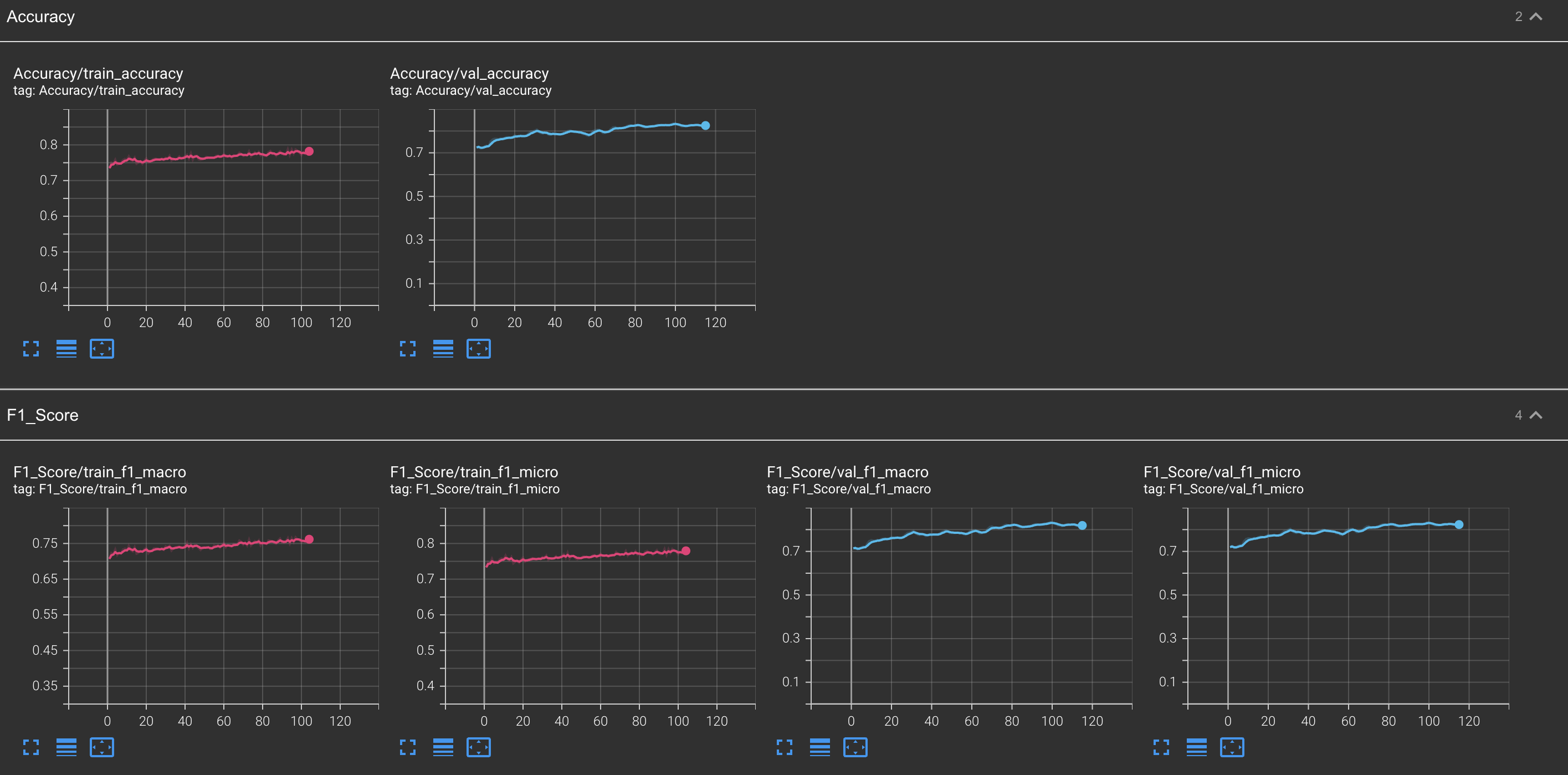
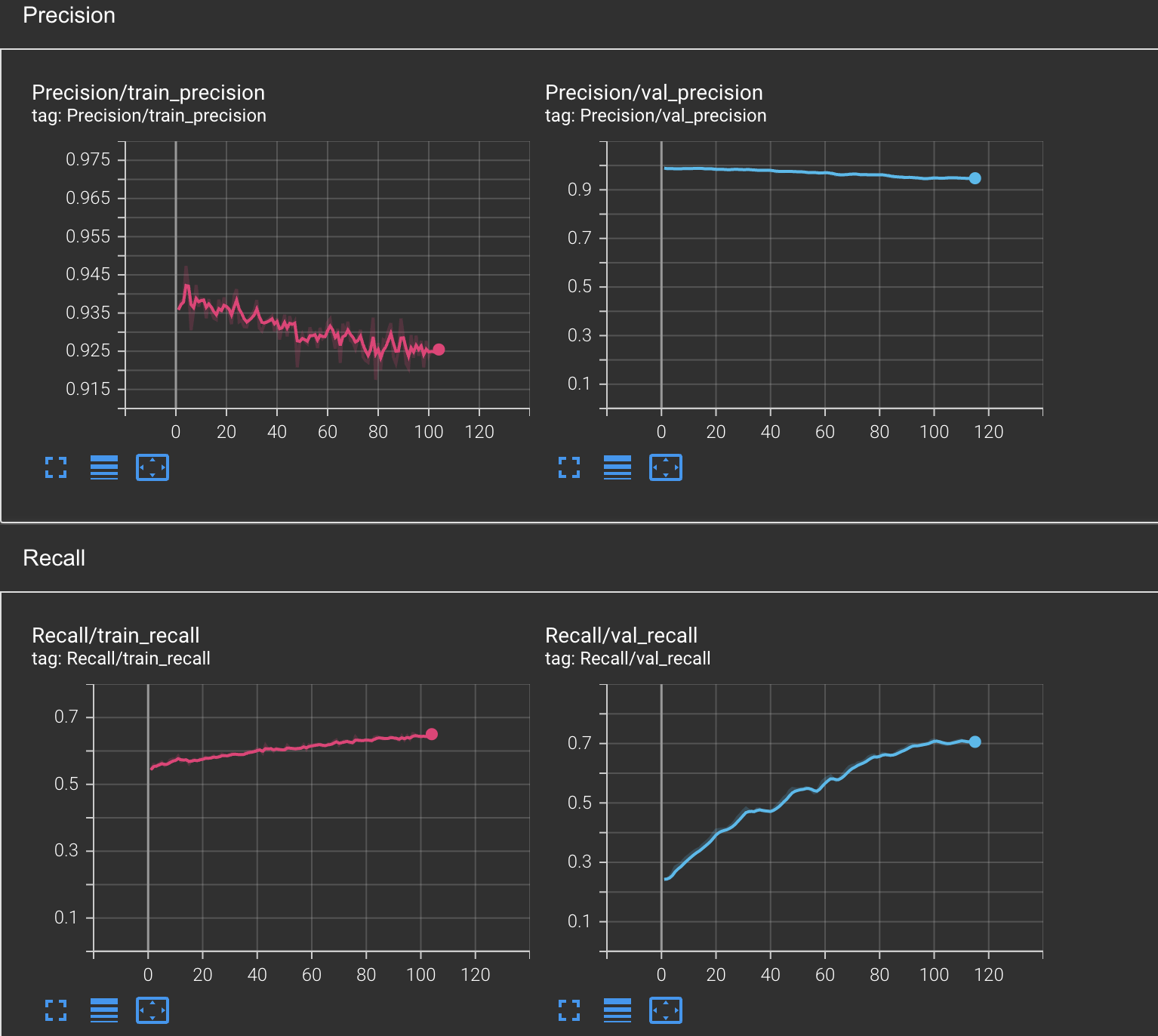
 For me, this is an indication that my model is learning fine.
For me, this is an indication that my model is learning fine.
But when I checked these metrics on an Unbatched training and Unbatched Validation these metrics are very low. These are not even 1%.
Unbatched dataset means I am not taking calculating these metrics over batches and not taking the average of metrics to calculate the final metrics which is what Tensorflow/Keras does during model training. I am calculating these metrics on a full dataset in a single run
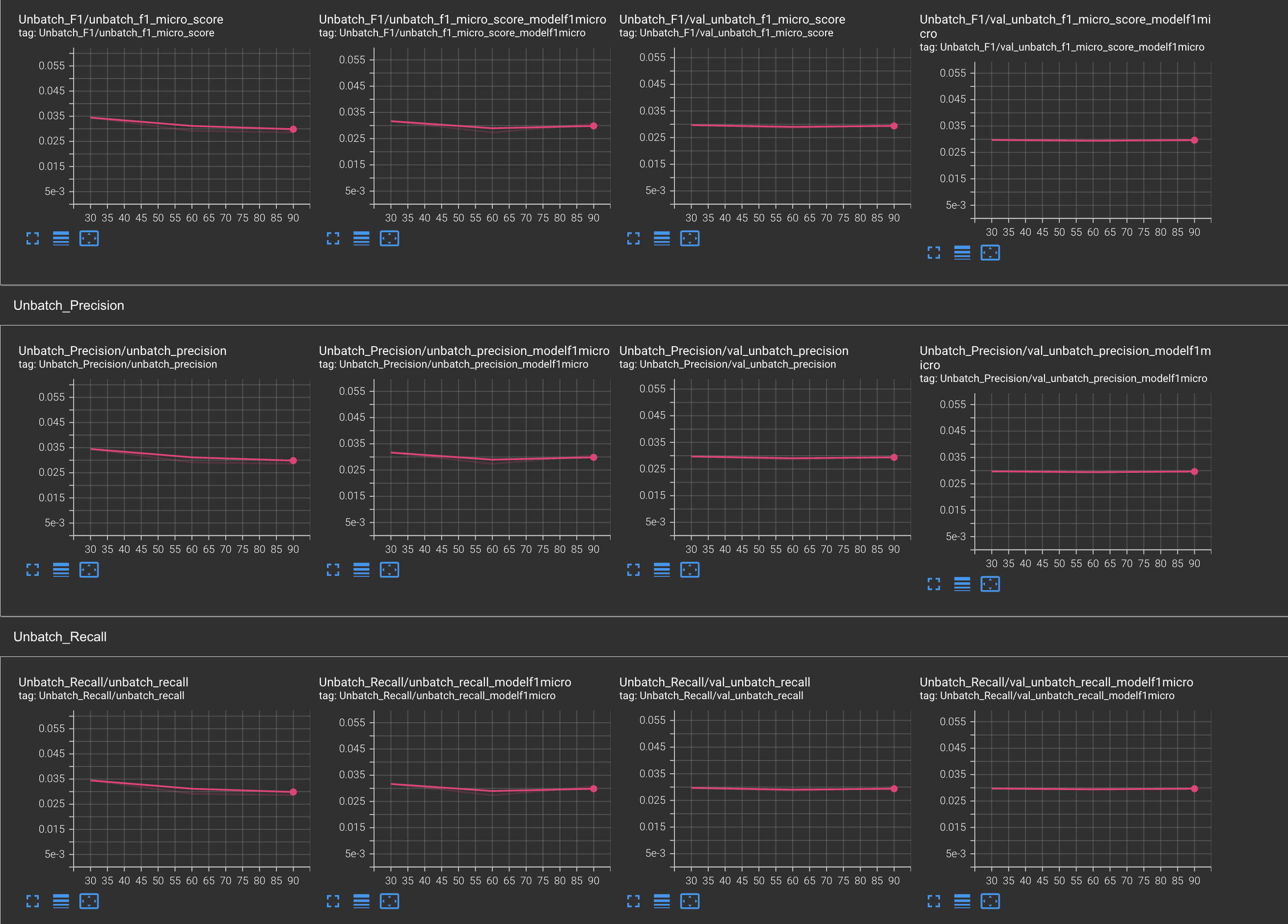
I am unable to find out what is causing this Behaviour. Please help me understand what is causing this difference and how to ensure that results are consistent on both, i.e. a minor difference is acceptable.
Code that I used for evaluating metrics My old code
def test_model(model, data, CLASSES, label_one_hot=True, average="micro",
threshold_analysis=False, thres_analysis_start_point=0.0,
thres_analysis_end_point=0.95, thres_step=0.05, classwise_analysis=False,
produce_confusion_matrix=False):
images_ds = data.map(lambda image, label: image)
labels_ds = data.map(lambda image, label: label).unbatch()
NUM_VALIDATION_IMAGES = count_data_items(tf_records_filenames=data)
cm_correct_labels = next(iter(labels_ds.batch(NUM_VALIDATION_IMAGES))).numpy() # get everything as one batch
if label_one_hot is True:
cm_correct_labels = np.argmax(cm_correct_labels, axis=-1)
cm_probabilities = model.predict(images_ds)
cm_predictions = np.argmax(cm_probabilities, axis=-1)
warnings.filterwarnings('ignore')
overall_score = f1_score(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)), average=average)
overall_precision = precision_score(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)), average=average)
overall_recall = recall_score(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)), average=average)
# cmat = (cmat.T / cmat.sum(axis=1)).T # normalized
# print('f1 score: {:.3f}, precision: {:.3f}, recall: {:.3f}'.format(score, precision, recall))
overall_test_results = {'overall_f1_score': overall_score, 'overall_precision':overall_precision, 'overall_recall':overall_recall}
if classwise_analysis is True:
label_index_dict = get_index_label_from_tf_record(dataset=data)
label_index_dict = {k:v for k, v in sorted(list(label_index_dict.items()))}
label_index_df = pd.DataFrame(label_index_dict, index=[0]).T.reset_index().rename(columns={'index':'class_ind', 0:'class_names'})
# Class wise precision, recall and f1_score
classwise_score = f1_score(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)), average=None)
classwise_precision = precision_score(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)), average=None)
classwise_recall = recall_score(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)), average=None)
ind_class_count_df = class_ind_counter_from_tfrecord(data)
ind_class_count_df = ind_class_count_df.merge(label_index_df, how='left', left_on='class_names', right_on='class_names')
classwise_test_results = {'classwise_f1_score':classwise_score, 'classwise_precision':classwise_precision,
'classwise_recall':classwise_recall, 'class_names':CLASSES}
classwise_test_results_df = pd.DataFrame(classwise_test_results)
if produce_confusion_matrix is True:
cmat = confusion_matrix(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)))
return overall_test_results, classwise_test_results, cmat
return overall_test_results, classwise_test_results
if produce_confusion_matrix is True:
cmat = confusion_matrix(cm_correct_labels, cm_predictions, labels=range(len(CLASSES)))
return overall_test_results, cmat
warnings.filterwarnings('always')
return overall_test_results
Just to ensure that my model testing function is correct I write a newer version of code in TensorFlow.
def eval_model(y_true, y_pred):
eval_results = {}
unbatch_accuracy = tf.keras.metrics.CategoricalAccuracy(name='unbatch_accuracy')
unbatch_recall = tf.keras.metrics.Recall(name='unbatch_recall')
unbatch_precision = tf.keras.metrics.Precision(name='unbatch_precision')
unbatch_f1_micro = tfa.metrics.F1Score(name='unbatch_f1_micro', num_classes=n_labels, average='micro')
unbatch_f1_macro = tfa.metrics.F1Score(name='unbatch_f1_macro', num_classes=n_labels, average='macro')
unbatch_accuracy.update_state(y_true, y_pred)
unbatch_recall.update_state(y_true, y_pred)
unbatch_precision.update_state(y_true, y_pred)
unbatch_f1_micro.update_state(y_true, y_pred)
unbatch_f1_macro.update_state(y_true, y_pred)
eval_results['unbatch_accuracy'] = unbatch_accuracy.result().numpy()
eval_results['unbatch_recall'] = unbatch_recall.result().numpy()
eval_results['unbatch_precision'] = unbatch_precision.result().numpy()
eval_results['unbatch_f1_micro'] = unbatch_f1_micro.result().numpy()
eval_results['unbatch_f1_macro'] = unbatch_f1_macro.result().numpy()
unbatch_accuracy.reset_states()
unbatch_recall.reset_states()
unbatch_precision.reset_states()
unbatch_f1_micro.reset_states()
unbatch_f1_macro.reset_states()
return eval_results
The results are nearly the same by using both of the functions.
Please suggest what is going on here.
CodePudding user response:
I think this sugesstion MAY help you, I am not sure. in this, you added
unbatch_accuracy.reset_states()
unbatch_recall.reset_states()
unbatch_precision.reset_states()
unbatch_f1_micro.reset_states()
unbatch_f1_macro.reset_states()
resetting states at each epoch maybe not be a cumulative one
CodePudding user response:
After spending many hours, I found the issue was due to the shuffle function. I was using the below function to shuffle, batch and prefetch the dataset.
def shuffle_batch_prefetch(dataset, prefetch_size=1, batch_size=16,
shuffle_buffer_size=None,
drop_remainder=False,
interleave_num_pcall=None):
if shuffle_buffer_size is None:
raise ValueError("shuffle_buffer_size can't be None")
def shuffle_fn(ds):
return ds.shuffle(buffer_size=shuffle_buffer_size, seed=108)
dataset = dataset.apply(shuffle_fn)
dataset = dataset.batch(batch_size, drop_remainder=drop_remainder)
dataset = dataset.prefetch(buffer_size=prefetch_size)
return dataset
Part of the function that causes the problem
def shuffle_fn(ds):
return ds.shuffle(buffer_size=shuffle_buffer_size, seed=108)
dataset = dataset.apply(shuffle_fn)
I removed the shuffle part and metrics are back as per the expectation. Function after removing the shuffle part
def shuffle_batch_prefetch(dataset, prefetch_size=1, batch_size=16,
drop_remainder=False,
interleave_num_pcall=None):
dataset = dataset.batch(batch_size, drop_remainder=drop_remainder)
dataset = dataset.prefetch(buffer_size=prefetch_size)
return dataset
Results after removing the shuffle part
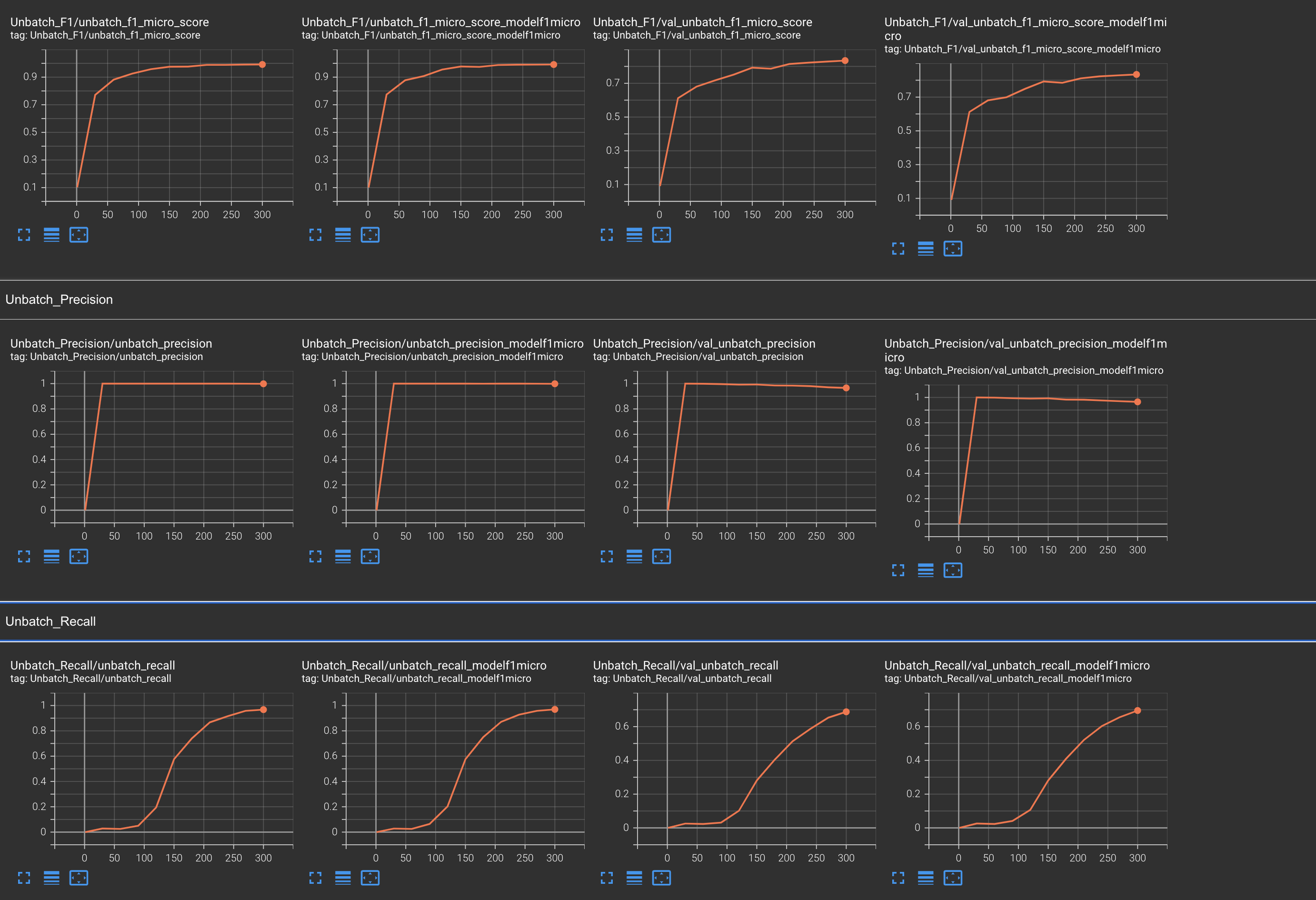
I am still not able to understand why shuffling causes this error. Shuffling was the best practice to follow before training your data. Although, I have already shuffled training data during data read time so removing this was not a problem for me