I'm trying to create a plot with five variables, three of which are air pollutants: PM2.5, NO2, and O3. I want the numbers to be subscripts, which is how these are written in most literature, but I've been trying every variation I can think of using square brackets, expression(), bquote(), and others and nothing is working. This is the simplified code I have right now:
risks$variable <- factor(risks$variable,
levels=c("O3","PM2.5","NO2",
"Diethyl","Dimethyl"),
labels=c(expression(O[3]),
expression(PM[2.5]),
expression(NO[2]),
"Diethyl",
"Dimethyl"))
ggplot(risks, aes(variable, est, ymin = est - 1.96*sd,
ymax = est 1.96*sd, col = q.fixed))
geom_pointrange(position = position_dodge(width = 0.75))
coord_flip()
Unfortunately, with everything I've tried the plot either shows the variable names with the square brackets around them, or the labels without brackets but the numbers still aren't subscripts. Any thoughts here?
CodePudding user response:
You need to assign the labels in the ggplot call. Since they're not being parsed, the subscripts aren't processed correctly.
library(ggplot2)
# Example data
df <- data.frame(variable = rep(c("O","NO"), 10),
est = rnorm(20))
# Make figure
ggplot(df, aes(x = variable, y = est)) geom_point()
scale_x_discrete(labels = c("O" = expression("O"[2]),
"NO" = expression("NO"[1])))
CodePudding user response:
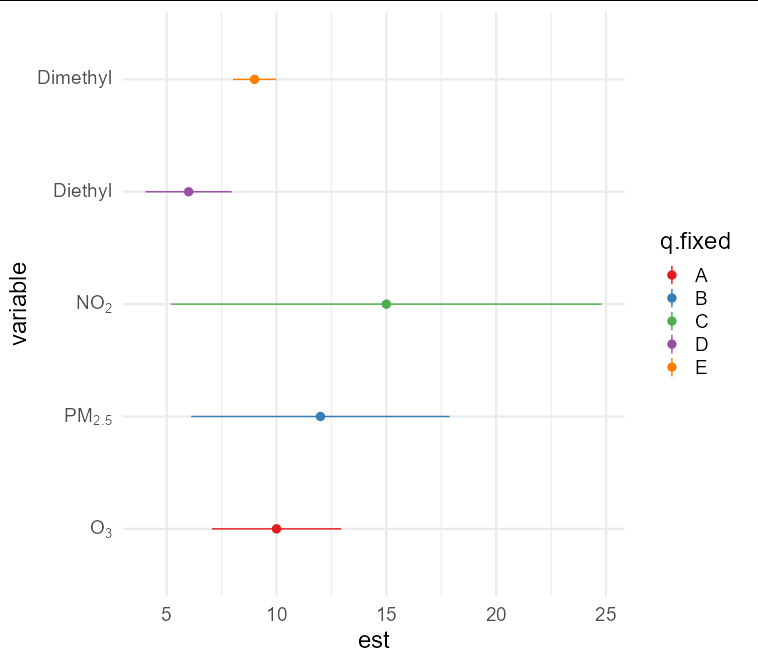
Obviously, we don't have your data, so here's a random set with the same names / structure:
risks <- data.frame(
variable = c("O3","PM2.5","NO2", "Diethyl","Dimethyl"),
est = c(10, 12, 15, 6, 9),
sd = c(1.5, 3, 5, 1, 0.5),
q.fixed = c("A", "B", "C", "D", "E")
)
Now let's convert your variable column to a factor using your own code:
risks$variable <- factor(risks$variable,
levels=c("O3","PM2.5","NO2",
"Diethyl","Dimethyl"),
labels=c(expression(O[3]),
expression(PM[2.5]),
expression(NO[2]),
"Diethyl",
"Dimethyl"))
Now we can plit the result. The secret here is to parse the x axis labels (which look like y axis labels due to the coord_flip. I've added a theme to make the labels more obvious.
ggplot(risks, aes(variable, est, ymin = est - 1.96*sd,
ymax = est 1.96*sd, col = q.fixed))
geom_pointrange(position = position_dodge(width = 0.75))
coord_flip()
scale_x_discrete(labels = ~parse(text = .x))
scale_color_brewer(palette = "Set1")
theme_minimal(base_size = 18)