I'm attempting to use a website to scrape a specific html table that contains the following information:
- Balance
- Addresses
- % Addresses (Total)
- Coins
- USD
- % Coins (Total)
The code that I am using is below:
url = "https://app.intotheblock.com/coin/AMP/deep-dive?group=ownership&chart=all"
r = requests.get(url)
html = r.text
soup = BeautifulSoup(html)
table = soup.find('table', {"class": "sc-lhVmIH fYUufF sc-cmTdod gUHuZc"})
rows = table.find_all('tr')
data = []
for row in rows[1:]:
cols = row.find_all('td')
cols = [ele.text.strip() for ele in cols]
data.append([ele for ele in cols if ele])
result = pd.DataFrame(data, columns=['Balance','Addresses','% Addresses (Total)','Coins','USD','% Coins (Total)'])
print(result)
I attempted to inspect the webpage so that I could grab the class type of the table but when I thought I found the html table I was looking for I keep getting an error on the following line "rows = table.find_all('tr')". This is telling me that I am not selecting the right class for the table that I would like to scrape.
I wrote code that would automatically login to the website, enter credentials, click the login button and navigate to the specific page that I would like to scrape and the table is returning back empty. The class type that I choose came after the table data so I thought that it was the correct class to use.
The specific link I am trying to scrape the data is below:
Link: 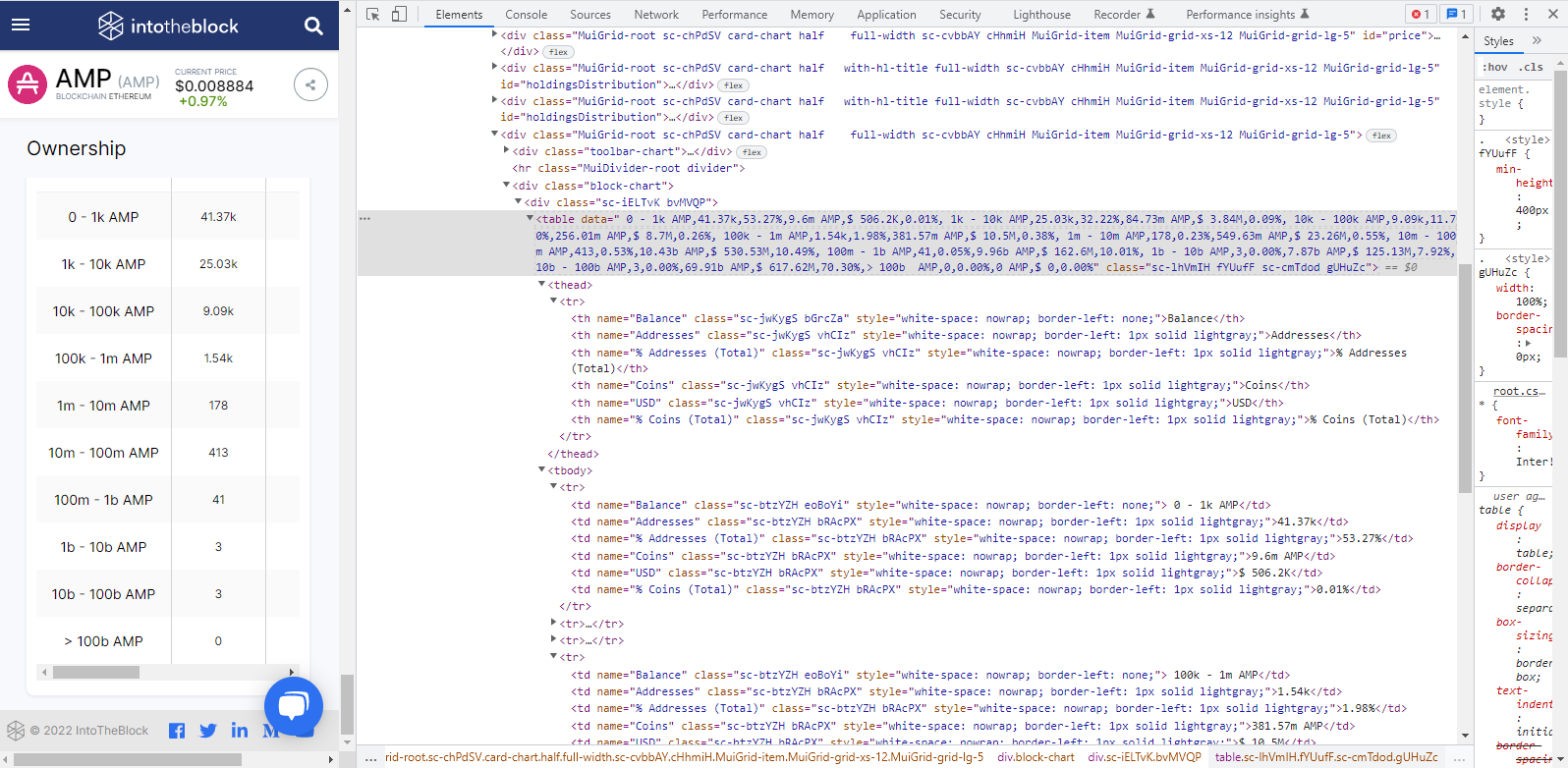
CodePudding user response:
You need JS to view that, so it is easier to scrape via the underlying API.
Google Chrome Inspect Network XHR then search api, find the one you need, then structure a python request to receive the json using the authorization token as such.
import requests
url = "https://services.intotheblock.com/api/internal/metrics/coin/8bdae7d9-b8ff-41a1-8229-2dd07f047845/ownership/holdings_distribution_matrix"
payload={}
headers = {
'Authorization': 'Bearer some long text'
}
request = requests.request("GET", url, headers=headers, data=payload)
request.json()