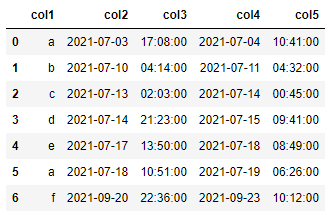
I want to group by consecutive values in col1 and for each group, select the earliest date and hour from col2 and col3 and the latest date and hour from col4 and col5.
Here is my data:
| col1 | col2 | col3 | col4 | col5 | |
|---|---|---|---|---|---|
| 0 | a | 2021-07-03 | 17:08 | 2021-07-04 | 10:41 |
| 1 | b | 2021-07-10 | 04:14 | 2021-07-11 | 04:32 |
| 2 | c | 2021-07-13 | 02:03 | 2021-07-14 | 00:45 |
| 3 | d | 2021-07-14 | 21:23 | 2021-07-15 | 02:59 |
| 4 | d | 2021-07-15 | 04:05 | 2021-07-15 | 09:41 |
| 5 | e | 2021-07-17 | 13:50 | 2021-07-18 | 08:49 |
| 6 | a | 2021-07-18 | 10:51 | 2021-07-18 | 12:27 |
| 7 | a | 2021-07-18 | 13:55 | 2021-07-19 | 06:26 |
| 8 | f | 2021-09-20 | 22:36 | 2021-09-20 | 23:19 |
| 9 | f | 2021-09-21 | 23:45 | 2021-09-23 | 10:12 |
Expected output:
| col1 | col2 | col3 | col4 | col5 | |
|---|---|---|---|---|---|
| 0 | a | 2021-07-03 | 17:08 | 2021-07-04 | 10:41 |
| 1 | b | 2021-07-10 | 04:14 | 2021-07-11 | 04:32 |
| 2 | c | 2021-07-13 | 02:03 | 2021-07-14 | 00:45 |
| 3 | d | 2021-07-14 | 21:23 | 2021-07-15 | 09:41 |
| 4 | e | 2021-07-17 | 13:50 | 2021-07-18 | 08:49 |
| 5 | a | 2021-07-18 | 10:51 | 2021-07-19 | 06:26 |
| 6 | f | 2021-09-20 | 22:36 | 2021-09-23 | 10:12 |
CodePudding user response:
This solution expects the dates to be sorted from the earliest to the latest, as in the provided example data.
from itertools import groupby
from io import StringIO
import pandas as pd
df = pd.read_csv(
StringIO(
"""col1 col2 col3 col4 col5
a 2021-07-03 17:08 2021-07-04 10:41
b 2021-07-10 04:14 2021-07-11 04:32
c 2021-07-13 02:03 2021-07-14 00:45
d 2021-07-14 21:23 2021-07-15 02:59
d 2021-07-15 04:05 2021-07-15 09:41
e 2021-07-17 13:50 2021-07-18 08:49
a 2021-07-18 10:51 2021-07-18 12:27
a 2021-07-18 13:55 2021-07-19 06:26
f 2021-09-20 22:36 2021-09-20 23:19
f 2021-09-21 23:45 2021-09-23 10:12
"""
),
delim_whitespace=True,
header=0,
)
# Group by consecutive values in col1
groups = [list(group) for key, group in groupby(df["col1"].values.tolist())]
group_end_indices = pd.Series(len(g) for g in groups).cumsum()
group_start_indices = (group_end_indices - group_end_indices.diff(1)).fillna(0).astype(int)
filtered_df = []
for start_ix, end_ix in zip(group_start_indices, group_end_indices):
group = df.iloc[start_ix:end_ix]
if group.shape[0] > 1:
group.iloc[0][["col4", "col5"]] = group.iloc[-1][["col4", "col5"]]
filtered_df.append(group.iloc[0])
filtered_df = pd.DataFrame(filtered_df).reset_index(drop=True)
print(filtered_df)
Output:
col1 col2 col3 col4 col5
0 a 2021-07-03 17:08 2021-07-04 10:41
1 b 2021-07-10 04:14 2021-07-11 04:32
2 c 2021-07-13 02:03 2021-07-14 00:45
3 d 2021-07-14 21:23 2021-07-15 09:41
4 e 2021-07-17 13:50 2021-07-18 08:49
5 a 2021-07-18 10:51 2021-07-19 06:26
6 f 2021-09-20 22:36 2021-09-23 10:12
CodePudding user response:
You could use the fact that these are datetimes and use pandas groupby to select the earlier dates from col2 col3 and later dates from col4 col5 for each group.
filtered_df = (
# convert each pair of columns to datetimes
df.assign(c1 = pd.to_datetime(df['col2'] ' ' df['col3']), c2 = pd.to_datetime(df['col4'] ' ' df['col5']))
# groupby consecutive col1 values and keep earliest c1 and latest c2 values
.groupby(df['col1'].shift().ne(df['col1']).cumsum()).agg({'col1': 'first', 'c1': 'min', 'c2': 'max'})
# split datetimes back into separate columns by dates and times
.set_index('col1', append=True).astype(str).stack().str.split(expand=True).unstack()
# rename columns
.set_axis(['col2', 'col4', 'col3', 'col5'], axis=1).sort_index(axis=1)
# bring col1 in as a column
.reset_index(level=1).reset_index(drop=True)
)
filtered_df