Hello I'm learning Python and Pandas, and I'm working on an exercise. I'm loading in 2 csv files and merging them into one dataframe.
import pandas as pd
# File to Load (Remember to Change These)
school_data_to_load = "Resources/schools_complete.csv"
student_data_to_load = "Resources/students_complete.csv"
# Read School and Student Data File and store into Pandas DataFrames
school_data_df = pd.read_csv(school_data_to_load)
student_data_df = pd.read_csv(student_data_to_load)
# Combine the data into a single dataset.
school_data_complete_df = pd.merge(student_data_df, school_data_df, how="left", on=["school_name", "school_name"])
school_data_complete_df.head()

The output looks like the picture above.
I'm trying to:
Calculate the percentage of students with a passing math score (70 or greater)
Calculate the percentage of students with a passing reading score (70 or greater)
Calculate the percentage of students who passed math and reading (% Overall Passing)
I'm looking to populate a new dataframe by looking at students who only got 70 or greater on their math and reading scores by using the loc command
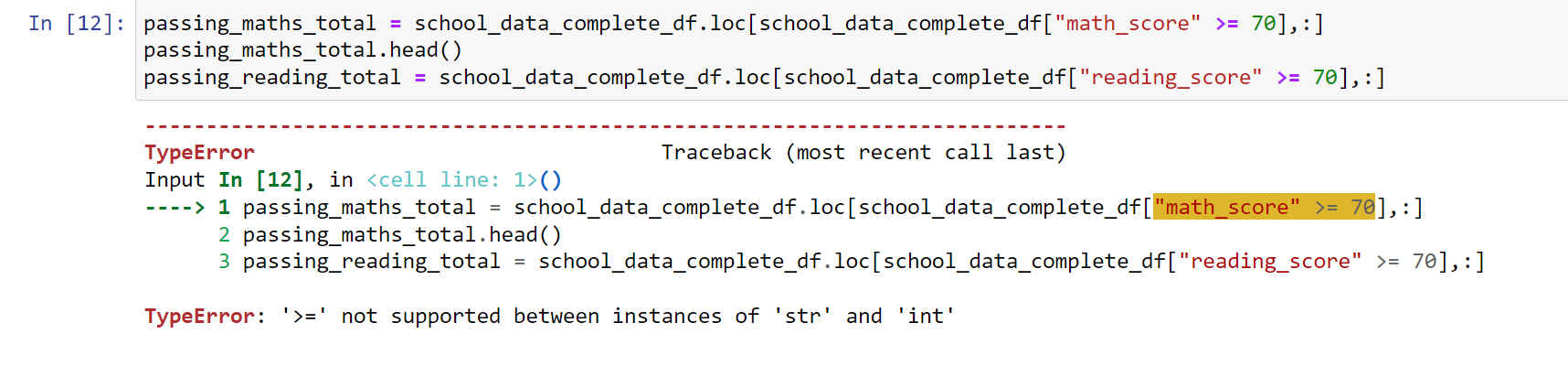
I got this error. I don't understand because the values in the columns should all be integers so why is it saying I'm trying to pass strings in there as well?
CodePudding user response:
You are not comparing the values in the column. You are just comparing "math_score" >= 70. There's a string on the left, and an integer on the right, hence your problem.
Fix the location of your angle brackets, and you should be good to go:
passing_maths_total = school_data_complete_df.loc[school_data_complete_df["math score"] >= 70]
Pandas broadcasts the result of the >= comparison, so comparing the Pandas Series school_data_complete_df["math score"] with 70 results in a boolean Pandas Series which can be used for indexing, e.g. in .loc.
The colon is unnecessary because the row index comes first in .loc anyways.
This solution is not tested.