I intend to count entities based on buckets defined for the metrics(columns).
The base data table:
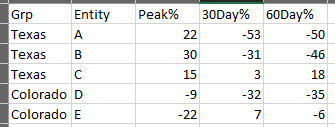
I need a count of entities based on defined buckets as -100 to -20, -20 to -10, -10 to 100 , for each column.
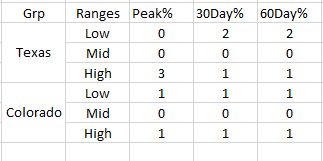
So, I guess the final output could be displayed as
dput of the raw data:
structure(list(Entity = c("A", "B", "C", "D", "E"), `Peak%` = c(22,
30, 15, -9, -22), `30Day%` = c(-53, -31, 3, -32, 7), `60Day%` = c(-50,
-46, 18, -35, -6)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-5L))
CodePudding user response:
If you want to maintain empty levels, here is a very similar data.table solution:
library(data.table)
lapply(dat[-1], cut, breaks = c(-100, -20, -10, 100), labels=c("Low", "Mid", "High")) |>
as.data.table() |>
melt(, measure=1:3, value.factor=TRUE) |>
dcast(value ~ variable, drop=FALSE, fill=0, fun=length)
#> value Peak% 30Day% 60Day%
#> 1: Low 1 3 3
#> 2: Mid 0 0 0
#> 3: High 4 2 2
Edit:
Based on the modified question, this would be one option:
dat <- structure(list(
Grp=rep(c("Texas", "Colorado"), each=3)[1:5],
Entity = c("A", "B", "C", "D", "E"),
`Peak%` = c(22, 30, 15, -9, -22),
`30Day%` = c(-53, -31, 3, -32, 7),
`60Day%` = c(-50, -46, 18, -35, -6)),
class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA, -5L))
library(data.table)
setDT(dat)
dat[, (colnames(dat)[-c(1:2)]) := lapply(dat[, -c(1:2)], cut, breaks = c(-100, -20, -10, 100), labels=c("Low", "Mid", "High"))]
melt(dat, measure=3:5, value.factor=TRUE, value.name = "Ranges") |>
dcast(Grp Ranges ~ variable, drop=FALSE, fill=0, fun=length)
#> Grp Ranges Peak% 30Day% 60Day%
#> 1: Colorado Low 1 1 1
#> 2: Colorado Mid 0 0 0
#> 3: Colorado High 1 1 1
#> 4: Texas Low 0 2 2
#> 5: Texas Mid 0 0 0
#> 6: Texas High 3 1 1
Created on 2022-07-21 by the reprex package (v2.0.1)
CodePudding user response:
base R and reshape2
as.data.frame(lapply(dat[-1], cut, breaks = c(-100, -20, -10, 100))) |>
reshape2::melt(c()) |>
reshape2::dcast(value ~ variable)
# Aggregation function missing: defaulting to length
# value Peak. X30Day. X60Day.
# 1 (-10,100] 4 2 2
# 2 (-100,-20] 1 3 3