Convert two rows to one row and two columns on dataframe using python.
Input:
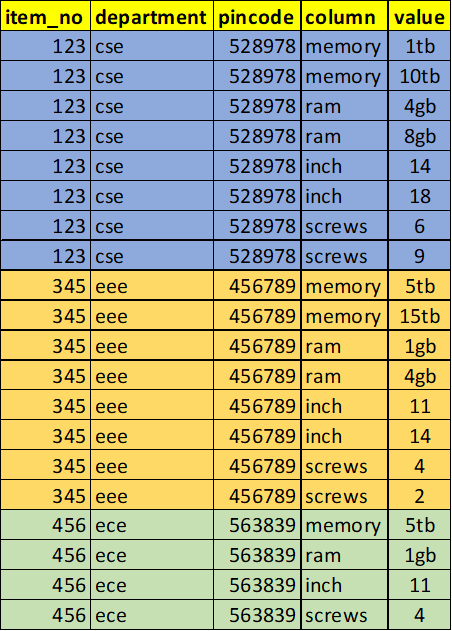
output
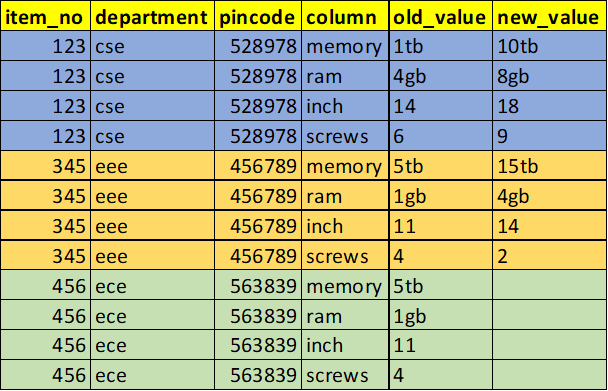
CodePudding user response:
Here is the explanation to your question.
import pandas as pd
import numpy as np
filename = "assets/test.csv"
data = pd.read_csv (
filename,
skiprows=[0],
header=None,
)
X = data.iloc[:, :-1].values
Y = data.iloc[:,-1].values
X = X.tolist()
Y = Y.tolist()
Z = []
for i in range(0,len(data),2):
L = X[i]
L.append(Y[i])
L.append(Y[i 1])
Z.append(L)
Z = np.array(Z)
data_ = pd.DataFrame(Z,index=None)
data_.to_csv("assets/test_.csv")
First the data (assuming will be stored in csv) will be read using pandas. Then, it will be segregated and converted to list for ease of manipulation. Later on the program is iterating for every other element in the list and appending to a new list. Finally the list is converted to numpy to be written to a new csv.
Note the following
- It is assumed that all even rows have their semi-duplicated underneath them.
- The headers are omitted but can be added by removing the attribute
skiprows=[0]
Feel free to comment if you have any question, and remember to accept/upvote if it answers your question.
CodePudding user response:
I made like this. You can add item_no 345 and 456 data. I've just used the sample data. Code:
#import he library
import pandas as pd
# sample df from your data
df = pd.DataFrame({
"item_no" : ["123", "123", "123", "123", "123", "123", "123", "123"],
"department": ["cse", "cse", "cse", "cse", "cse", "cse", "cse", "cse"],
"pincode": [528978, 528978, 528978, 528978, 528978, 528978, 528978, 528978],
"column" : ["memory", "memory", "ram", "ram", "inch", "inch", "screws", "screws"],
"value":["1tb", "10tb", "4gb", "8gb", "14", "148", "6", "9"]
})
# create new empty list
new_list = []
for idx, item in enumerate(df.values):
for idx2, item2 in enumerate(new_list):
if (item[0]==item2[0] and
item[1]==item2[1] and
item[2]==item2[2] and
item[3]==item2[3]):
new_list[idx2] = [item[0], item[1], item[2], item[3], item2[4], item[4]]
else:
new_list.append([item[0], item[1], item[2], item[3], item[4]])
#filter new_list
new_list = [x for x in new_list if len(x) > 5]
# Create the pandas DataFrame
df = pd.DataFrame(new_list,
columns = ["item_no", "department", "pincode", "column", "old_value", "new_value" ])
# print dataframe.
print(df)
Output:
item_no department pincode column old_value new_value
0 123 cse 528978 memory 1tb 10tb
1 123 cse 528978 ram 4gb 8gb
2 123 cse 528978 inch 14 148
3 123 cse 528978 screws 6 9
CodePudding user response:
You can use pandas.pivot_table with aggfunc=list and param values='value' then create new dataframe base aggregate values and index of previous dataframe.
df = df.pivot_table(index=['item_no','department','pincode', 'column'],
values=['value'], aggfunc=list)
df = pd.DataFrame(df['value'].tolist(), index=df.index,
columns=['old_value', 'new_value']
).reset_index().fillna('')
print(df)
item_no department pincode column old_value new_value
0 123 cse 528978 inch 14 18
1 123 cse 528978 memory 1tb 10tb
2 123 cse 528978 ram 4gb 8gb
3 123 cse 528978 screws 6 9
4 345 eee 456789 inch 11 14
5 345 eee 456789 memory 5tb 15tb
6 345 eee 456789 ram 1gb 4gb
7 345 eee 456789 screws 4 2
8 456 ece 563839 inch 11
9 456 ece 563839 memory 5tb
10 456 ece 563839 ram 1gb
11 456 ece 563839 screws 4