Here is my problem statement -
I have columnA with data set like
import pandas as pd
df = pd.DataFrame({
'columnA': ['DD22HAHTL1NXX---', 'DD22HATNT1N--D3F', 'DD22HATNT1N--B3F', 'DD22HAHTL1N--A3F', 'DD22HATNT1N--C1F', 'DD22HAHTL1N--A3F', 'DD22HATNT1N--B3F', 'DD22HAHTL1N--A3F', 'DD22HAHTL1N--A3E', 'DD22HAHTL1N--A3F', 'DD22HAHTL1N--B3F', 'DD22HAHTL1N--A3F', 'DD22HAHTL1N--A3F', 'DD22HAHTL1NZZ---', 'DD22HAHTL1N--A3E']})
I am trying to create a new columnB with the substring of columnA but with a catch. The condition is,
If the last 3 characters of each row is --- then I need to extract XX , i.e 12th and 13th characters and add it in new columnB else I need to capture the last 3 characters and add them to columnB . My desired output will look like this -
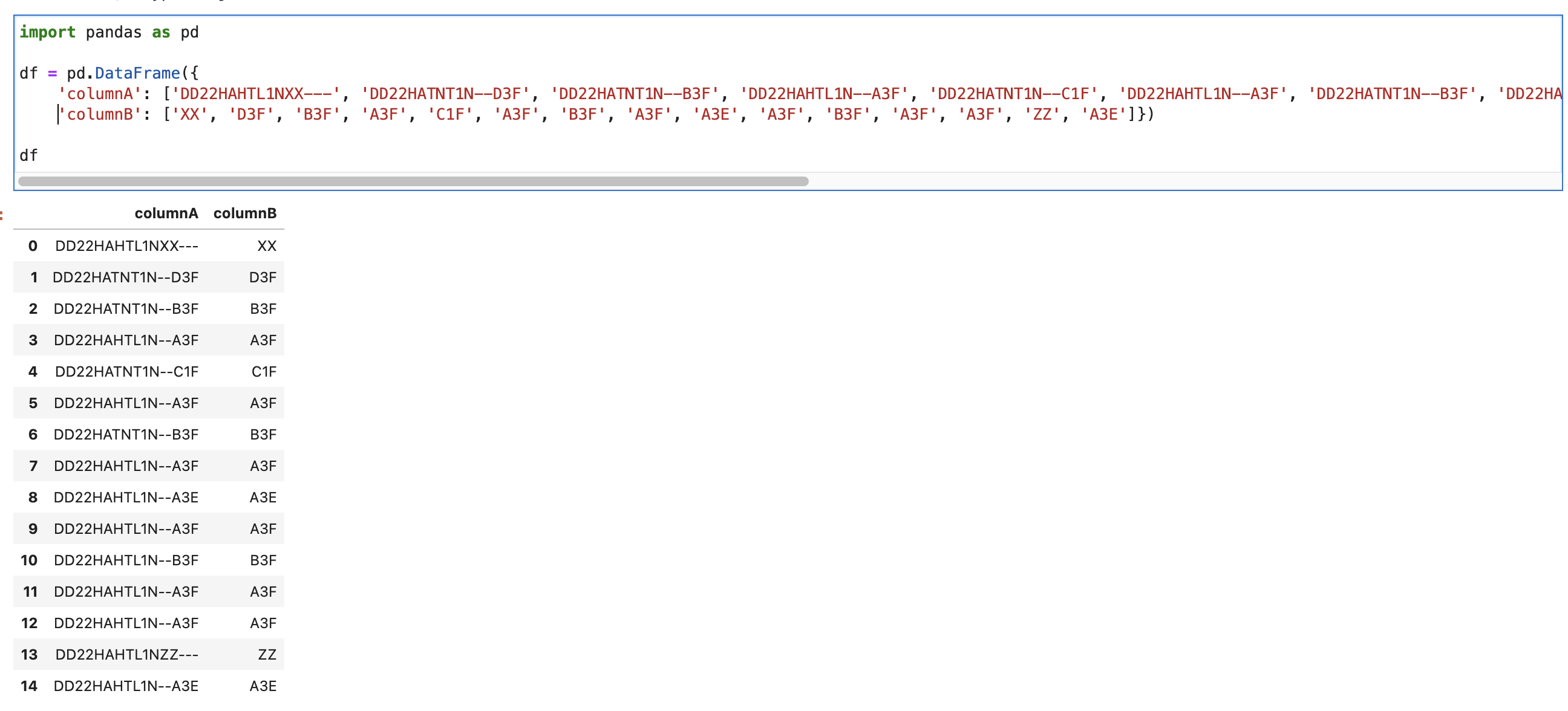
How can i create this new columnB efficiently without using any loops?
I tried this and worked for me for only 1 case:
df['columnB'] = df.columnA.str[-3:]
df[columnB] = df.['columnA'].str.extract('([A-Za,z]{2}---)', expand=True)
This gave me last 3 charecters of all the columns which are not ending with '---' but with the column ending with '---' , I got it as is which is wrong. I also tried str.extract with regex but it gave me correct values for all the rows ending with '---' but not the others. Please help.
CodePudding user response:
You could use np.where
import numpy as np
df['columnB'] = np.where(df['columnA'].str.endswith('---'), df['columnA'].str.slice(11,13), df['columnA'].str.slice(-3))
print(df)
Result
columnA columnB
0 DD22HAHTL1NXX--- XX
1 DD22HATNT1N--D3F D3F
2 DD22HATNT1N--B3F B3F
3 DD22HAHTL1N--A3F A3F
4 DD22HATNT1N--C1F C1F
5 DD22HAHTL1N--A3F A3F
6 DD22HATNT1N--B3F B3F
7 DD22HAHTL1N--A3F A3F
8 DD22HAHTL1N--A3E A3E
9 DD22HAHTL1N--A3F A3F
10 DD22HAHTL1N--B3F B3F
11 DD22HAHTL1N--A3F A3F
12 DD22HAHTL1N--A3F A3F
13 DD22HAHTL1NZZ--- ZZ
14 DD22HAHTL1N--A3E A3E