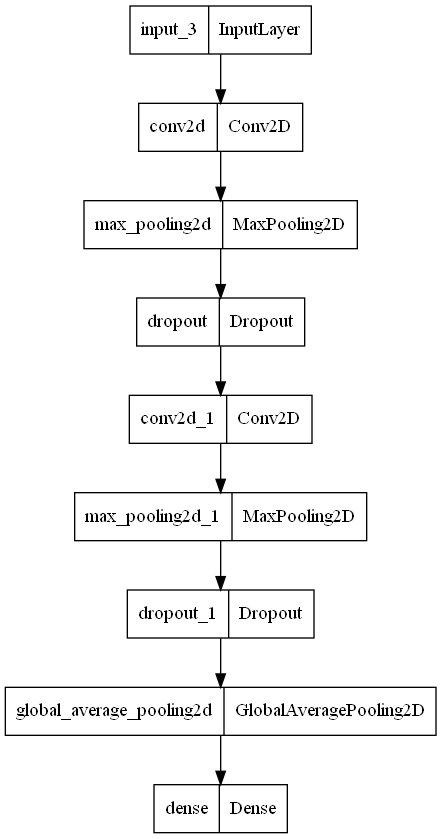
I am new to machine learning and I am currently trying to create a siamese network that can predict the similarity of brand logos. I have a dataset with ~210.000 brand logos. The CNN for the siamese network looks like the following:
def build_cnn(inputShape, embeddingDim=48):
# specify the inputs for the feature extractor network
inputs = Input(shape=inputShape)
# define the first set of CONV => RELU => POOL => DROPOUT layers
x = Conv2D(64, (2, 2), padding="same", activation="relu")(inputs)
x = MaxPooling2D(pool_size=(5, 5))(x)
x = Dropout(0.3)(x)
# second set of CONV => RELU => POOL => DROPOUT layers
x = Conv2D(64, (2, 2), padding="same", activation="relu")(x)
x = MaxPooling2D(pool_size=2)(x)
x = Dropout(0.3)(x)
pooledOutput = GlobalAveragePooling2D()(x)
outputs = Dense(embeddingDim)(pooledOutput)
# build the model
model = Model(inputs, outputs)
model.summary()
plot_model(model, to_file=os.path.sep.join([config.BASE_OUTPUT,'model_cnn.png']))
# return the model to the calling function
return model
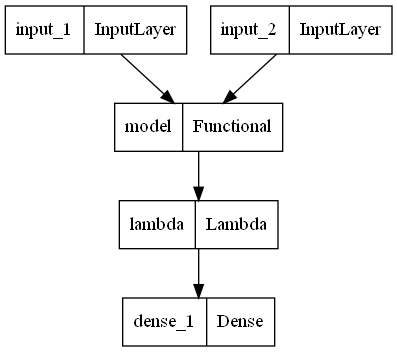
The siamese network looks like this (the model here is the cnn described above):
imgA = Input(shape=config.IMG_SHAPE)
imgB = Input(shape=config.IMG_SHAPE)
featureExtractor = siamese_network.build_cnn(config.IMG_SHAPE)
featsA = featureExtractor(imgA)
featsB = featureExtractor(imgB)
distance = Lambda(euclidean_distance)([featsA, featsB])
outputs = Dense(1, activation="sigmoid")(distance)
model = Model(inputs=[imgA, imgB], outputs=outputs)
My first test was with 800 positive and 800 negative pairs and the accuracy and loss looks like this:
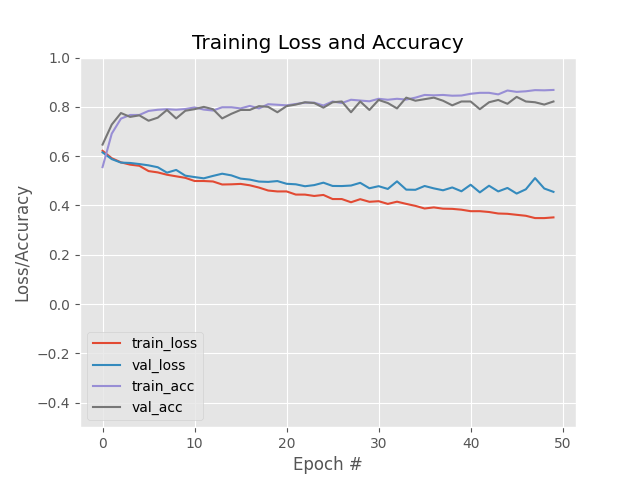
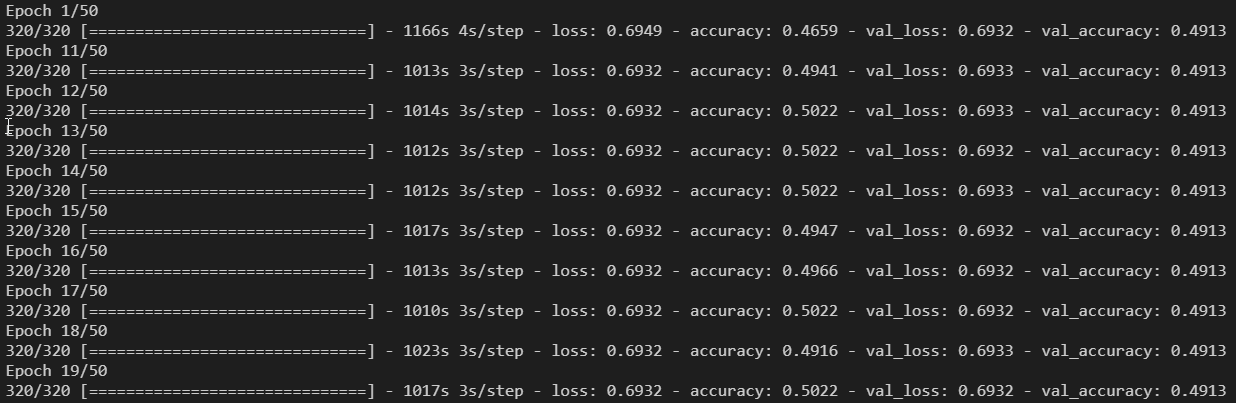
My thoughts to this were that there is some overfitting happening and my approach was to create more training data (2000 positive and negative pairs) and train the model again, but unfortunately the model was not improving at all after, even after 20 epochs.
For both cases I used the following to train my network:
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
print("[INFO] training model...")
history = model.fit(
[pairTrain[:, 0], pairTrain[:, 1]], labelTrain[:],
validation_data=([pairTest[:, 0], pairTest[:, 1]], labelTest[:]),
batch_size=10,
shuffle=True,
epochs=50)
I cannot figure out what is happening here, so I am really gratefull for every help. My question here is why is the siamese network learning (or at least it looks like it is learning) with less training data, but as soon as I add more the accuracy is constant and not improving at all?
EDIT According to Albertos comment I tried it with selu (still not working):
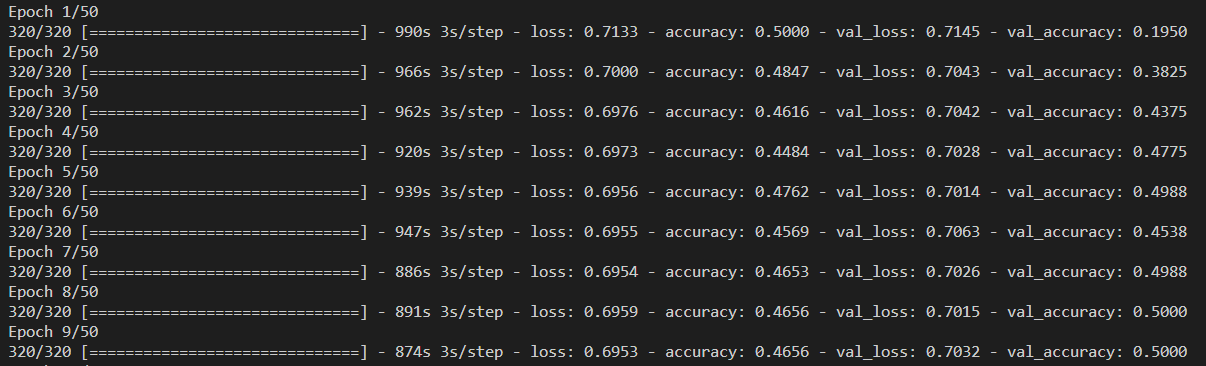
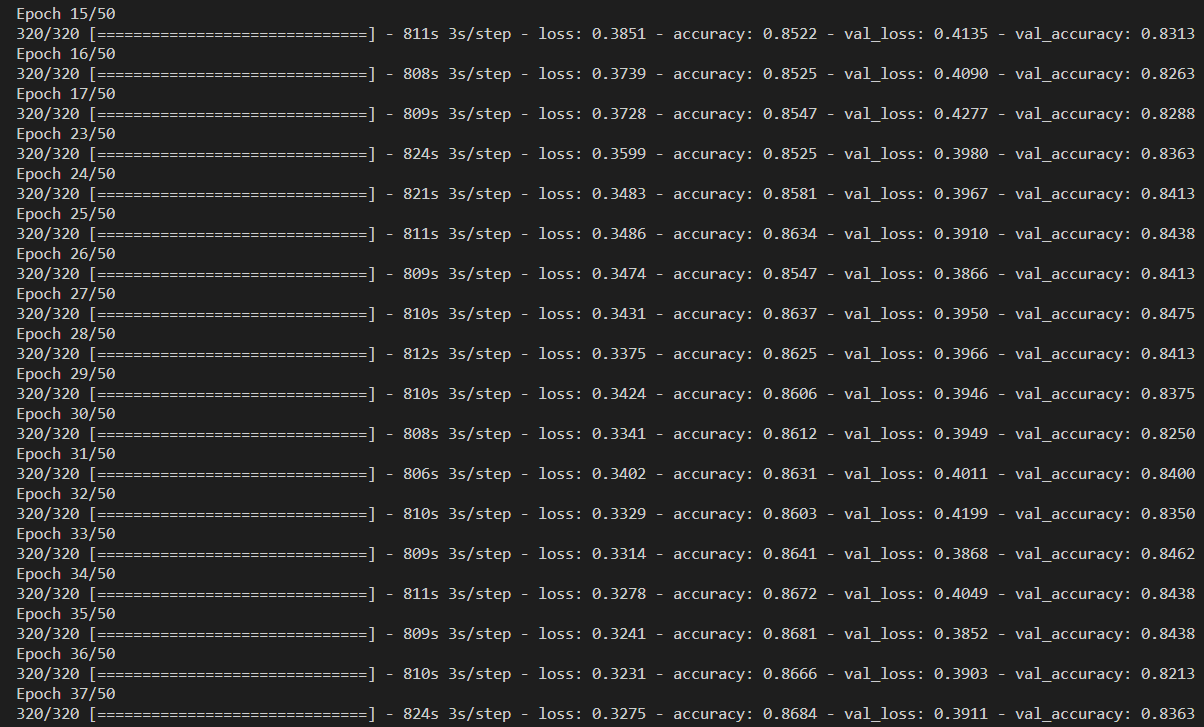
EDIT2 With LeakyReLU it looks like this:
CodePudding user response:
I've seen this happening other times, idk if it's a case but this Github issue has literally the same loss
As in that case, I think that is more a problem of initialization, so at this point I think you should use He-initialziation, or non-saturating activation function (for example, try tf.keras.layers.LeakyReLU or tf.keras.activations.selu)