I have a DataFrame that I build row-by-row (by necessity). My issue is that at the end, all dtypes are object. This is not so if the DataFrame is created with all the data at once.
Let me explain what I mean.
import pandas as pd
from IPython.display import display
# Example data
cols = ['P/N','Date','x','y','z']
PN = ['10a1','10a2','10a3']
dates = pd.to_datetime(['2022-07-01','2022-07-03','2022-07-05'])
xd = [0,1,2]
yd = [1.1,1.2,1.3]
zd = [-0.8,0.,0.8]
# Canonical way to build DataFrame (if you have all the data ready)
dg = pd.DataFrame({'P/N':PN,'Date':dates,'x':xd,'y':yd,'z':zd})
display(dg)
dg.dtypes
Here's what I get. Note the correct dtypes:
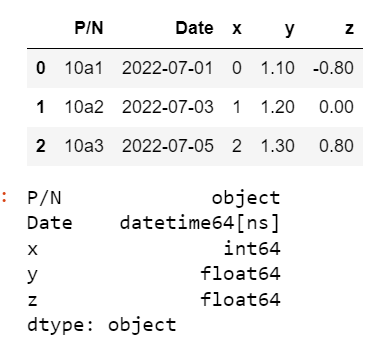
OK, now I do the same thing row-by-row:
# Build empty DataFrame
cols = ['P/N','Date','x','y','z']
df = pd.DataFrame(columns=cols)
# Add rows in loop
for i in range(3):
new_row = {'P/N':PN[i],'Date':pd.to_datetime(dates[i]),'x':xd[i],'y':yd[i],'z':zd[i]}
# deprecated
#df = df.append(new_row,ignore_index=True)
df = pd.concat([df,pd.DataFrame([new_row])],ignore_index=True)
display(df)
df.dtypes
Note the [] around new_row, otherwise you get a stupid error. (I really don't understand the deprecation of append, BTW. It allows for much more readable code)
But now I get this: This isn't the same as above, all the dtypes are object!
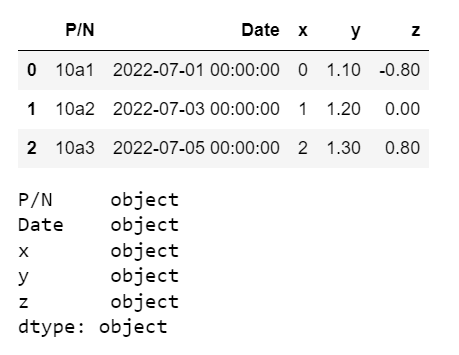
The only way I found to recover my dtypes is to use infer_objects:
# Recover dtypes by using infer_objects()
dh = df.infer_objects()
dh.dtypes
And dh is now the same as dg.
Note that even if I do
df = pd.concat([df,pd.DataFrame([new_row]).infer_objects()],ignore_index=True)
above, it still does not work. I believe this is due to a bug in concat: when an empty DataFrame is concat'ed to a non-empty DataFrame, the resulting DataFrame fails to take over the dtypes of second DataFrame. We can verify this with:
pd.concat([pd.DataFrame(),df],ignore_index=True).dtypes
and all dtypes are still object.
Is there a better way to build a DataFrame row-by-row and have the correct dtypes inferred automatically?
CodePudding user response:
Your initial dataframe df = pd.DataFrame(columns=cols) columns are all of type object because it has no data to infer dtypes from. So you need to set them with astype. Like @mozway commented it is recommended to use a list to add the from the loop.
I expect this to work for you:
import pandas as pd
cols = ['P/N','Date','x','y','z']
dtypes = ['object', 'datetime64[ns]', 'int64', 'float64', 'float64']
PN = ['10a1','10a2','10a3']
dates = pd.to_datetime(['2022-07-01','2022-07-03','2022-07-05'])
xd = [0,1,2]
yd = [1.1,1.2,1.3]
zd = [-0.8,0.,0.8]
df = pd.DataFrame(columns=cols).astype({c:d for c,d in zip(cols,dtypes)})
new_rows = []
for i in range(3):
new_row = [PN[i], pd.to_datetime(dates[i]), xd[i], yd[i], zd[i]]
new_rows.append(new_row)
df_new = pd.concat([df, pd.DataFrame(new_rows, columns=cols)], axis=0)
print(df_new)
print(df_new.info())
Output:
P/N Date x y z
0 10a1 2022-07-01 0 1.1 -0.8
1 10a2 2022-07-03 1 1.2 0.0
2 10a3 2022-07-05 2 1.3 0.8
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3 entries, 0 to 2
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 P/N 3 non-null object
1 Date 3 non-null datetime64[ns]
2 x 3 non-null int64
3 y 3 non-null float64
4 z 3 non-null float64
dtypes: datetime64[ns](1), float64(2), int64(1), object(1)
memory usage: 144.0 bytes