I have this CSV:
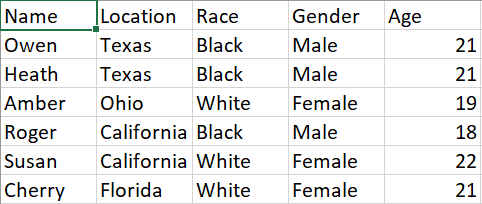
and I turned it into a graph using NetworkX:
attr_df = pd.read_csv("names.csv")
# changing all datatypes of every column to string
attr_df = attr_df.astype(str)
G = nx.Graph()
for index, row in attr_df.iterrows():
#create dict from row
row_dict = row.to_dict()
#pop name and unpack dict to pass to graph
G.add_node(row_dict.pop('Name'), **row_dict)
# Connect Graph with Weighted Edges based on how many node properties are similar
G.add_edge('Owen', 'Heath', weight=4/4, common='Location= Texas, Race= Black, Gender= Male, Age= 21')
G.add_edge('Owen', 'Roger', weight=2/4, common = 'Race= Black, Gender= Male')
G.add_edge('Owen', 'Cherry', weight=1/4, common='Age= 21')
G.add_edge('Heath', 'Roger', weight=2/4, common='Race= Black, Gender= Male')
G.add_edge('Heath', 'Cherry', weight=1/4, common='Age= 21')
G.add_edge('Amber', 'Susan', weight=2/4, common='Race= White, Gender= Female')
G.add_edge('Amber', 'Cherry', weight=2/4, common='Race= White, Gender= Female')
G.add_edge('Roger', 'Susan', weight=1/4, common='Location= California')
G.add_edge('Susan', 'Cherry', weight=2/4, common='Race= White, Gender= Female')
# Visualize Graph (Matplotlib)
weights = nx.get_edge_attributes(G, 'weight')
common = nx.get_edge_attributes(G, 'common')
nx.draw(G, with_labels = True)
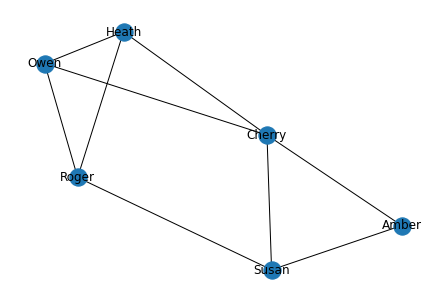
I want to create a loop that adds edges, weights (based on common properties) and attributes (which is a list of their common properties). I know I could eye the csv and create the edges from there, but as the CSV grows this would be more tedious. I'm not sure how to go about creating that for loop for creating those edges.
CodePudding user response:
Probably not the fastest way, but it works:
from itertools import combinations
row_dicts = [
{"Name": "Owen", "Location": "Texas", "Race": "Black", "Gender": "Male", "Age": "21"},
{"Name": "Heath", "Location": "Texas", "Race": "Black", "Gender": "Male", "Age": "21"},
{"Name": "Amber", "Location": "Ohio", "Race": "White", "Gender": "Female", "Age": "19"},
{"Name": "Roger", "Location": "California", "Race": "Black", "Gender": "Male", "Age": "18"},
{"Name": "Susan", "Location": "California", "Race": "White", "Gender": "Female", "Age": "22"},
{"Name": "Cherry", "Location": "Florida", "Race": "White", "Gender": "Female", "Age": "21"},
]
for P1, P2 in combinations(row_dicts, 2):
common = {key: v1 for (key, v1), v2 in zip(P1.items(), P2.values()) if v1 == v2}
if common:
print(f"G.add_edge('{P1['Name']}', '{P2['Name']}', weight={len(common)}/4, common={common})")
# G.add_edge(P1['Name'], P2['Name'], weight=len(common)/4, common=str(common))
Gives the output:
G.add_edge('Owen', 'Heath', weight=4/4, common={'Location': 'Texas', 'Race': 'Black', 'Gender': 'Male', 'Age': '21'})
G.add_edge('Owen', 'Roger', weight=2/4, common={'Race': 'Black', 'Gender': 'Male'})
G.add_edge('Owen', 'Cherry', weight=1/4, common={'Age': '21'})
G.add_edge('Heath', 'Roger', weight=2/4, common={'Race': 'Black', 'Gender': 'Male'})
G.add_edge('Heath', 'Cherry', weight=1/4, common={'Age': '21'})
G.add_edge('Amber', 'Susan', weight=2/4, common={'Race': 'White', 'Gender': 'Female'})
G.add_edge('Amber', 'Cherry', weight=2/4, common={'Race': 'White', 'Gender': 'Female'})
G.add_edge('Roger', 'Susan', weight=1/4, common={'Location': 'California'})
G.add_edge('Susan', 'Cherry', weight=2/4, common={'Race': 'White', 'Gender': 'Female'})
A few notes:
- Please don't eval that f-string, but call G.add_edge directly. This was just for illustrative purposes.
itertools.combinationstakes any iterable, so you should be able, to directly feed the rows as an iterator to the loop and not having to save it in memory as a list, like I did for this example. This can be relevant if you have a lot of data.- The algorithm relies on all the rows having the same keys in the same order. If you can't guarantee that, you'd need to change the dictionary-comprehension a bit.