I just started using Python and I am trying to improve myself by engaging in different projects.
At the moment I am trying to create a work allocation tool. I loaded 2 xlsx files as df.
In df "dfau" there is a list of the employees with their capacity left and the languages that they speak.
| Employees | Capacity Left | Languages |
|---|---|---|
| E1 | 0 | EN, GER |
| E2 | -11 | EN, IT, ES |
| E3 | 6 | EN, CH |
| E4 | 2 | EN, ES, FR |
| E5 | -1 | EN |
| E6 | 1 | EN |
| E7 | -9 | EN, GER |
| E8 | 8 | EN, GER |
In df "dfln" there is a list of the languages.
| Languages |
|---|
| EN |
| IT |
| ES |
| GER |
| CH |
| FR |
| NL |
| PT |
I would like to look for the languages listed in "dfln" into "dfau" and add the count of these languages as a second column in "dfln" (and this is where I am stuck).
Afterwards, in "dfln", I would also like to add a column which would show the capacity per each language by summing the capacities left of each employee which can speak the language.
The employees which have a "Capacity Left" below 1 should not be counted nor summed.
This is how it should appear:
| Languages | Count | Capacity |
|---|---|---|
| EN | 6 | 85 |
| IT | 0 | 0 |
| ES | 3 | 15 |
| GER | 1 | 8 |
| CH | 1 | 6 |
| FR | 1 | 2 |
| NL | 1 | 45 |
| PT | 2 | 13 |
I tried to re-write the code in different ways but still this is where I got stuck (the result remains the basic dfln.
import pandas as pd
dfau = pd.read_excel (r'C:\Users\Projects\pywp\SampleAu.xlsx', sheet_name='Employees')
dfln = pd.read_excel (r'C:\Users\Projects\pywp\SampleAu.xlsx', sheet_name='Languages')
LCount=0
dfln.insert(1,"Count",LCount)
for language in dfln["Languages"]:
if dfau.loc[dfau["Languages"].str.contains(language, case=False)] is True:
LCount =1
print(dfln)
What can I try next?
CodePudding user response:
I cannot make sense of the final output. However, you can achieve what you are asking by running the following code:
dfIn['Count'] = 0
dfIn['Capacity'] = 0
for idx,row in dfIn.iterrows():
dfIn.iloc[idx,1] = dfau['Languages'][dfau['Capacity Left'] >= 1].str.contains(row.Languages).sum()
dfIn.iloc[idx, 2] = dfau['Capacity Left'][dfau['Capacity Left'] >= 1][dfau['Languages'].str.contains(row.Languages)].sum()
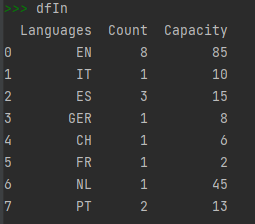
Notice that the final output looks like this, and not what you posted above: