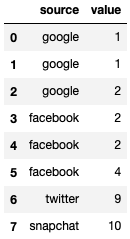
I have a pandas dataframe which has a 'source' column as shown in the table below. I want to normalize its values and create a new column called 'derived'.
| source | value | derived |
|---|---|---|
| 1 | ||
| 1 | ||
| googlechannel | 2 | |
| 2 | ||
| 2 | ||
| lt_Facebook | 4 | |
| 9 | other | |
| snapchat | 10 | other |
I tried the code but it is giving me error.
import pandas as pd
data_dict = {'source':['google','Google','googlechannel','facebook','Facebook','lt_Facebook','twitter','snapchat'],
'value':[1,1,2,2,2,4,9,10]}
data = pd.DataFrame.from_dict(data_dict)
def normalize_source(data):
if data['source'].str.lower().str.contains('facebook'):
return 'facebook'
elif data['source'].lower().str.contains('google'):
return 'google'
else:
return 'other'
data.loc[:,'derived'] = data.apply(normalize_source,axis=1)
data.head()
I am getting the following error:
AttributeError: 'str' object has no attribute 'str'
CodePudding user response:
you need to make use of __ contains __ here is your updated code
data_dict = {'source':['google','Google','googlechannel','facebook','Facebook','lt_Facebook','twitter','snapchat'],
'value':[1,1,2,2,2,4,9,10]}
data = pd.DataFrame.from_dict(data_dict)
def normalize_source(data):
if data['source'].lower().__contains__('facebook'):
return 'facebook'
elif data['source'].lower().__contains__('google'):
return 'google'
else:
return 'other'
data.loc[:,'derived'] = data.apply(normalize_source,axis=1)
data.head()
source value derived
0 google 1 google
1 Google 1 google
2 googlechannel 2 google
3 facebook 2 facebook
4 Facebook 2 facebook
CodePudding user response:
You are trying to apply a function which, as coded, takes a whole DataFrame.
Here is a fix:
def normalize_source(x):
x = x.lower()
if 'facebook' in x:
return 'facebook'
elif 'google' in x:
return 'google'
return 'other'
data = data.assign(derived=data['source'].apply(normalize_source))
>>> data
source value derived
0 google 1 google
1 Google 1 google
2 googlechannel 2 google
3 facebook 2 facebook
4 Facebook 2 facebook
5 lt_Facebook 4 facebook
6 twitter 9 other
7 snapchat 10 other
Alternative (for the specific problem at hand):
data = data.assign(
derived=data['source']
.str.lower()
.str.extract(r'(google|facebook)')
.fillna('other')
)
Depending on the number of matching possibilities, this could be faster (as regex builds an optimized parser).
CodePudding user response:
How about a conditional replacement via regular expression? In particular,
companyList = ['facebook', 'google', 'twitter', 'snapchat']
for compName in companyList:
data['source'] = data['source'].str.lower().replace(r'(^.*{}.*$)'.format(compName), compName, regex=True)
yields
data