I am having difficulty understanding the lock behaviour difference in the following examples, which cause me to have to resolve a deadlock.
I use (updlock,holdlock) for the common scenario of "select first, update/delete later". It might be relevant that in this specific case what is going to happen "later" is delete.
First, let me set up a case where everything works fine.
As a "control panel query", let's create a very simple table, add some rows, and also prepare a lock selection query based on ashman786's 
It just has a single "Clustered Index Delete" operator with an equality seek predicate on id to tell it the row to delete.
The locks taken out in this case are an IX lock on the table, an IX lock on the page containing the row, and finally an X lock on the key of the row to be deleted. No U locks are taken at all.
When using the temp table the execution plan looks as follows.
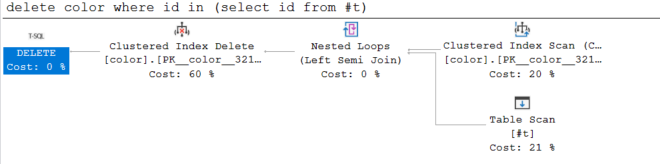
It reads each row from color in turn and acquires a U lock on it. If the semi join operator finds that there was a match for that row in the temp table the U lock is converted to an X lock and the row is deleted. Otherwise the U lock is released.
If the execution plan was driven by the temp table instead then it could avoid reading and locking unneeded rows in color.
One way of doing this would be to write the query as
DELETE color
FROM color WITH (forceseek)
WHERE id IN (SELECT #t.id
FROM #t)
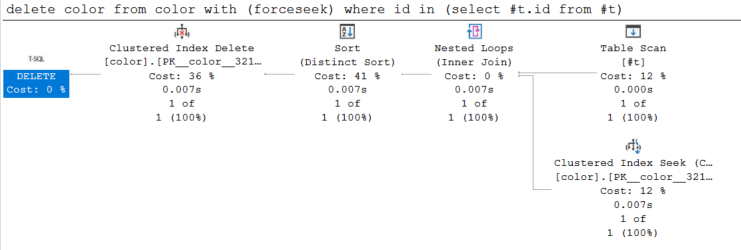
The execution plan now reads the one row in #t - checks whether it exists in color (taking a U lock on just that row) and then deletes it.
As there is no constraint on #t ensuring that id is unique it removes duplicates first rather than potentially attempting to delete the same row multiple times.