When I am scraping a weather website there are 2 "sections". When i do Humd = soup.select_one('section:-soup-contains("%")').section.text it checks the first section but the information i want is in the second section. How do I make it select the second section instead of searching and selecting the first?
How would i get the 42%? I have tried if soup contains '%' go to div, then the span and the text but it returns morning. Code below.
Humd = soup.select_one('section:-soup-contains("%")').div.span.text
The website: 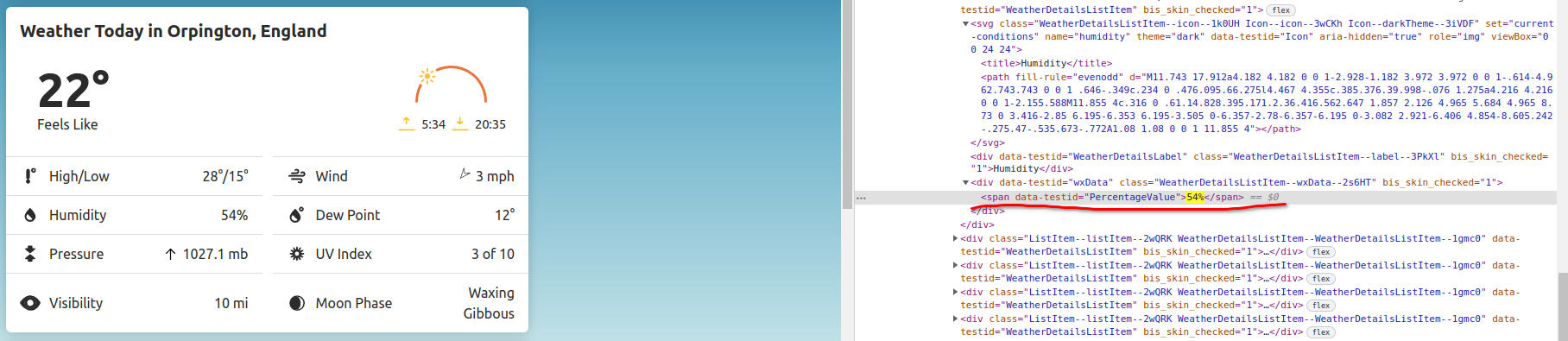
btw this site blocked in my country and i need to change my ip with python for testing this row, but i didn't do it yet.
CodePudding user response:
Select your elements more specific and use also the parent that contains Humidity:
soup.select_one('.TodayDetailsCard--detailsContainer--16Hg0 div:-soup-contains("Humidity")').span.text
Example
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent': 'Mozilla/5.0'}
url = 'https://weather.com/en-GB/weather/today/l/12ad1b2264138ebcb368cc8f5b7435cb276f7cdea8de4cf37f5bd9c22070aa76'
soup = BeautifulSoup(requests.get(url, headers=headers).text)
soup.select_one('.TodayDetailsCard--detailsContainer--16Hg0 div:-soup-contains("Humidity")').span.text
CodePudding user response:
The following code will reliably retrieve the value next to 'Humidity':
import requests
from bs4 import BeautifulSoup
url = "https://weather.com/en-GB/weather/today/l/12ad1b2264138ebcb368cc8f5b7435cb276f7cdea8de4cf37f5bd9c22070aa76"
r = requests.get(url)
soup = BeautifulSoup(r.text, 'html.parser')
hum = soup.find('div', string='Humidity').next_sibling
print(hum.text)
Result:
54%
Documentation for beautifulSoup can be found at https://www.crummy.com/software/BeautifulSoup/bs4/doc/#