I have my input data as below:
import pandas as pd
df = pd.DataFrame({
"Pillar": ["block", "segment", "block", "block", "segment",
"segment", "block", "block", "block"],
"Pillar ID": [1, 1, 1, 2, 2, 3, 2, 1, 1],
"Distance" : [1.5, 3, 4, 5, 7, 7.8, 9, 3, 6]
})
df
# Pillar Pillar ID Distance
# 0 Block 1 1.5
# 1 Segment 1 3
# 2 Block 1 4
# 3 Block 2 5
# 4 Segment 2 7
# 5 Segment 3 7.8
# 6 Block 2 9
# 7 Block 1 3
# 8 Block 1 6
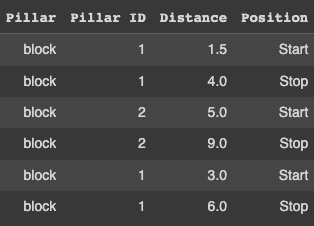
I want an output to get all the "Block" with two consecutive equal "Pillar ID" and assign "start" to the block with the lesser distance among the two consecutive blocks with same ID and assign "stop" to the block with the greater distance among the two consecutive blocks with same ID to have an output as below:
# Pillar Pillar ID Distance Position
# 0 Block 1 1.5 Start
# 2 Block 1 4 Stop
# 3 Block 2 5 Start
# 6 Block 2 9 Stop
# 7 Block 1 3 Start
# 8 Block 1 6 Stop
CodePudding user response:
Check Below code:
df.sort_values(['Pillar'], inplace=True)
df['Pillar ID_Shift'] = (df['Pillar ID'] != df.groupby(['Pillar'])['Pillar ID'].shift()).cumsum()
df['Position'] = np.where(df['Distance'] == df.groupby(['Pillar','Pillar ID_Shift'])['Distance'].transform('min'), 'Start', 'Stop')
df[df['Pillar'] == 'block'][['Pillar', 'Pillar ID', 'Distance', 'Position']]
Output: