I'm working with a set of data which has almost 60 columns (Text/Address/Numbers). After processing the data using 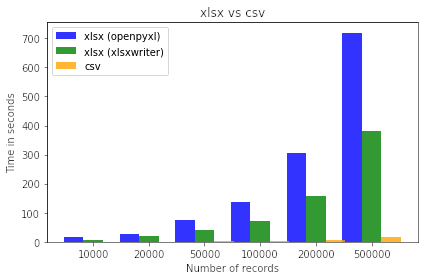
Is this the normal and expected behavior of .to_excel or there is something wrong here? is there any way to debug and solve this problem?
I have to be able to generate xlsx files for ~300K to ~600K records in matter of seconds, but as you can see it takes me around 6 minutes to generate an excel file for about 500K records.
The hardware that I'm using to generate these files has 16 Core of CPU, and 64 GB of memory.
CodePudding user response:
According to pandas.DataFrame.to_excel docs engine value might be either openpyxl or xlsxwriter, as you use latter one I suggest to test engine='openpyxl' vs engine='xlsxwriter'.
CodePudding user response:
I found a slightly faster solution, than just using engine='xlsxwriter'
import pandas as pd
from xlsxwriter.workbook import Workbook
def export_excel(df: pd.DataFrame, file_path_out: str):
workbook = Workbook(file_path_out)
worksheet = workbook.add_worksheet()
worksheet.write_row(0, 0, [col for col in df.columns])
for index, row in df.iterrows():
worksheet.write_row(index 1, 0, [col for col in row])
workbook.close()
The following table shows the runtime for three methods for 100 to 50k rows of random data (with 60 cols). The measured time is in seconds. openpyxl and xlsxwriter are df.export_excel(engine=...) calls and export_excel is my proposed code, above. Its not a game changer... but its faster
row count: openpyxl, xlsxwriter, export_excel
100: 0.1272597312927246, 0.15707993507385254, 0.12616825103759766
1000: 1.1917698383331299, 0.8460557460784912, 0.7760021686553955
10000: 12.29027795791626, 8.1415114402771, 6.129252195358276
25000: 32.34258818626404, 23.32529616355896, 18.124294996261597
50000: 63.35693168640137, 40.77235984802246, 30.406764268875122
using workbook = Workbook(file_path_out, {'constant_memory': True}) will improve the runtimes even more (but not really much: 1s faster for 25k rows=