As known all levels of cache L1/L2/L3 on modern x86_64 are 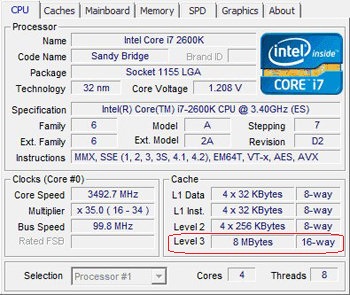
CodePudding user response:
This is possible because cache L3 can't contain the same physical memory area as page of process 1 and as page of process 2 at the same time.
Huh what? If both processes have a page mapped, they can both hit in the cache for the same line of physical memory.
That's part of the benefit of Intel's multicore designs using large inclusive L3 caches. Coherency only requires checking L3 tags to find cache lines in E or M state in another core's L2 or L1 cache.
Getting data between two cores only requires writeback to L3. I forget where this is documented. Maybe http://agner.org/optimize/ or What Every Programmer Should Know About Memory?. Or for cores that don't share any level of cache, you need a transfer between different caches at the same level of the cache hierarchy, as part of the coherency protocol. This is possible even if the line is "dirty", with the new owner assuming responsibility for eventually writing-back the contents that don't match DRAM.
The same cache line mapped to different virtual addresses will always go in the same set of the L1 cache. See discussion in comments: L2 / L3 caches are physically-index as well as physically tagged, so aliasing is never a problem. (Only L1 could get a speed benefit from virtual indexing. L1 cache misses aren't detected until after address translation is finished, so the physical address is ready in time to probe higher level caches.)
Also note that the discussion in comments incorrectly mentions Skylake lowering the associativity of L1 cache. In fact, it's the Skylake L2 cache that's less associative than before (4-way, down from 8-way in SnB/Haswell/Broadwell). L1 is still 32kiB 8-way as always: the maximum size for that associativity that keeps the page-selection address bits out of the index. So there's no mystery after all.
Also see another answer to this question about HT threads on the same core communicating through L1. I said more about cache ways and sets there.