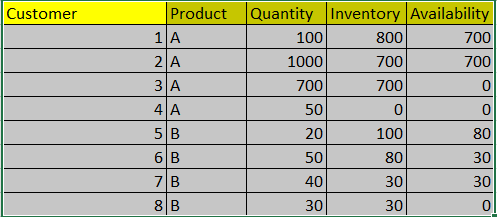
problem: need to calculated deliverables(availability in the dataset).When a customer purchases some quantity of a product it will be subtracted from the inventory and shown as availability. This availability will be the new inventory. When the next customer comes and buys the same product if it is greater than the inventory, we don't subtract it and the inventory will be the same else if the quantity is less than inventory we subtract quantity from inventory .This activity must be done in a first in first out method.
what i tried:
i have sorted the data on date field(which is not in the sample)to achieve FIFO.Then created a master table with distinct products and their inventory, done a iteration which gave me the correct solution. below is the code:
master_df = df[['product','inventory']].drop_duplicates()
master_df['free'] = df['inventory']
df['deliverable']=np.NaN
for i,row in df.iterrows():
if i00==0:
print(i)
try:
available = master_df[row['product']==master_df['product']]['free'].reset_index(drop=True).iloc[0]
if available-row['quantity']>=0:
df.at[i,'deliverable']=available-row['quantity']
a = master_df.loc[row['product']==master_df['product']].reset_index()['index'].iloc[0]
master_df.at[a,'free'] = available-row['quantity']
else:
df.at[i,'deliverable']=available
except Exception as e:
print(i)
print(e)
print((df.columns))
df = df.fillna(0)
for this iteration to complete it takes so much time and this needed to be done in a far lesser time(because of the time limit in aws lambda) can you guys help me to optimise this code without the help of for loop.
CodePudding user response:
Try .groupby with custom function:
def fn(x):
rv, current = [], x["inventory"].iat[0]
for requested_quantity, inv in zip(x["quantity"], x["inventory"]):
if requested_quantity <= inv:
current = inv - requested_quantity
rv.append(current)
x["deliverable"] = rv
df.groupby("product", as_index=False).apply(fn)
print(df)
Prints:
customer product quantity inventory availability deliverable
0 1 A 100 800 700 700.0
1 2 A 1000 700 700 700.0
2 3 A 700 700 0 0.0
3 4 A 50 0 0 0.0
4 5 B 20 100 80 80.0
5 6 B 50 80 30 30.0
6 7 B 40 30 30 30.0
7 8 B 30 30 0 0.0