I have yearly average closing values for an asset in a dataframe, and I need to find the structural breaks in the time series. I intended to do this using the stats model 'season_decompose' method but I am having trouble implementing it.
Example data below
from statsmodels.tsa.seasonal import seasonal_decompose
data = {'Year':['1991','1992','1993','1994','1995','1996','1997','1998','1999','2000','2001','2002','2003','2004'],'Close':[11,22,55,34,447,85,99,86,83,82,81,34,33,36]}
df = pd.DataFrame(data)
df['Year'] = df['Year'].astype(str)
sd = seasonal_decompose(df)
plt.show()
ValueError: You must specify a period or x must be a pandas object with a DatetimeIndex with a freq not set to None
When I change the 'Year' column to date time, I get the following issue:
TypeError: float() argument must be a string or a number, not 'Timestamp'
I do not know what the issue is. I have no missing values? Secondary to this, does anybody know a more efficient method to identify structural breaks in time series data?
Thanks
CodePudding user response:
The problem is that you need to set column Year as the index after converting the string values to datetime (from the ValueError message: a pandas object with a DatetimeIndex).
So, e.g.:
from statsmodels.tsa.seasonal import seasonal_decompose
import pandas as pd
data = {'Year':['1991','1992','1993','1994','1995','1996','1997','1998','1999','2000','2001','2002','2003','2004'],'Close':[11,22,55,34,447,85,99,86,83,82,81,34,33,36]}
df = pd.DataFrame(data)
df['Year'] = pd.to_datetime(df['Year'])
df.set_index('Year', drop=True, inplace=True)
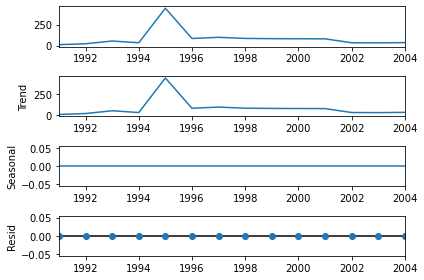
sd = seasonal_decompose(df)
sd.plot()
Plot: