I am wondering in a pandas dataframe how to groupby and apply aggregation to a specific columns but at the same time get respective values of another column, which wasnt part of the groupby or aggregation process.
For example, in this example I want to groupby "species" and take the min of "sepal_length" but at the same time display the respective values of "petal_width_class" column.
import seaborn as sns
iris = sns.load_dataset("iris")
iris["petal_width_class"] = [np.random.choice(["a","b"]) for _ in range(0,iris.shape[0])]
iris = iris.sample(10)
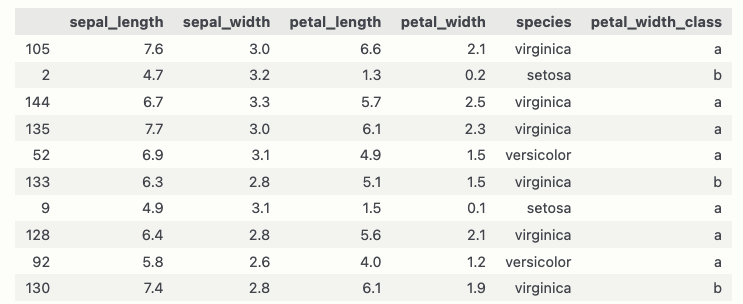
# now I can apply groupby and aggrgation like this, but I also want to see the values of petal_width_class
iris.groupby(["species"])[["sepal_length"]].min()
# from what I understand doing this wont work as it gives, in this case, the min value for each column seperately.
iris.groupby(["species"])[["petal_width_class","sepal_length"]].min()
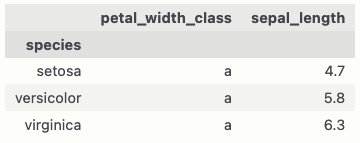
CodePudding user response:
The way to do that is to find the index of the min row and then extract the information you need:
# Get index of row with min sepal_length for each group
idx = iris.groupby(["species"])["sepal_length"].idxmin()
# Extract data for those rows
iris.loc[idx, ["species", "petal_width_class", "sepal_length"]]