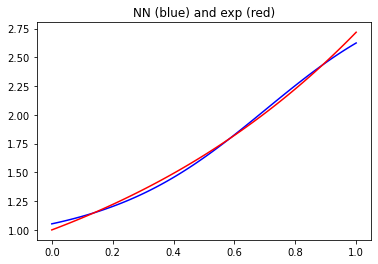
The following code works, converges and the neural net approximates the exponential on the interval from 0 to 1:
# code works
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# fit an exponential
n = 101
x = np.linspace(start=0, stop=1, num=n)
y_e = np.exp(x)
# any odd neural net with sufficient degrees of freedom
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1]),
tf.keras.layers.Dense(units=50, activation="softmax"),
tf.keras.layers.Dense(units=1)
])
# loss function
def loss(y_true, y_pred):
L_ode = tf.reduce_mean(tf.square(y_pred - y_true), axis=-1)
return L_ode
model.compile('adam', loss)
model.fit(x, y_e, epochs=100, batch_size=1)
y_NN = model.predict(x).flatten()
plt.plot(x, y_NN, color='blue')
plt.plot(x, y_e, color='red')
plt.title('NN (blue) and exp (red)')
Now I redefine the loss function and replace y_true by tf.zeros(n) in the model.fit. But this code - which should do the same thing - runs nicely but converges to a constant:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# fit an exponential
n = 101
x = np.linspace(start=0, stop=1, num=n)
y_e = np.exp(x)
# any odd neural net with sufficient degrees of freedom
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1]),
tf.keras.layers.Dense(units=50, activation="softmax"),
tf.keras.layers.Dense(units=1)
])
# loss function
def loss(y_true, y_pred):
L_ode = tf.reduce_mean(tf.square((y_pred - y_e) - y_true), axis=-1)
return L_ode
model.compile('adam', loss)
model.fit(x, tf.zeros(n), epochs=100, batch_size=1)
y_NN = model.predict(x).flatten()
plt.plot(x, y_NN, color='blue')
plt.plot(x, y_e, color='red')
plt.title('NN (blue) and exp (red)')
Where is the mistake?
Background: I would like to approximate solutions of odes with neural nets and therefore define my own loss-function. The above is a very reduced example of the "zero degree ode" y(x) = exp(x).
CodePudding user response:
I think your problem may be that you are using a global variable (y_e) in the second version of your loss function. There's no guarantee, or even reasonable expectation, that the value of this will be updated in the right way, batch by batch, when the loss function is called.
Loss has to be calculated from y_true and y_pred (plus you can use values that do not change during the course of the training)
CodePudding user response:
As discussed above, the issue is with the sampling of batches, the loss function sees random samples from the x that you provide to the fit function, so you cannot have a y value in the loss that is a global variable, because you do not know which value that should be.
But luckily y_true in the loss function can be multidimensional, see