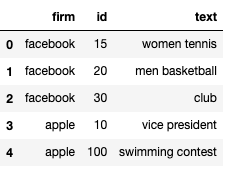
I have a dataframe with 10000 rows that look like below:
import numpy as np
df=pd.DataFrame(np.array([['facebook', '15',"women tennis"], ['facebook', '20',"men basketball"], ['facebook', '30','club'],
['apple', "10","vice president"], ['apple', "100",'swimming contest']]),columns=['firm','id','text'])
I'd like to save each firm into a separate JSON file. So the json file for Facebook looks like below, with the file name written as "firm.json" (e.g. facebook.json). The same will be for other firms, such as Apple.
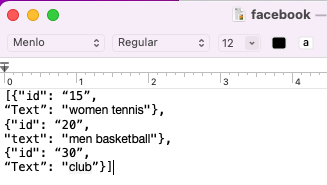
Sorry, I am still a beginner to Pandas, is there a way to do so effectively?
CodePudding user response:
You can do:
json_cols = df.columns.drop('firm').tolist()
json_records = df.groupby('firm')[json_cols].apply(
lambda x:x.to_json(orient='records'))
Then for 'facebook':
facebook_json = json_records['facebook']
'[{"id":"15","text":"women tennis"},
{"id":"20","text":"men basketball"},
{"id":"30","text":"club"}]'
for 'apple':
apple_json = json_records['apple']
'[{"id":"10","text":"vice president"},{"id":"100","text":"swimming contest"}]'
Save all at once
for col, records in json_records.iteritems():
with open(f"{col}.json", "w") as file:
file.write(records)
CodePudding user response:
import pandas as pd
import numpy as np
import json
df = pd.DataFrame(
np.array([
['facebook', '15',"women tennis"],
['facebook', '20',"men basketball"],
['facebook', '30','club'],
['apple', "10","vice president"],
['apple', "100",'swimming contest']]
), columns=['firm','id','text']
)
firms = set(df.firm)
for firm in firms:
df_firm = df[df.firm == firm]
d = []
for _, r in df_firm.iterrows():
d.append({'id': r.id, 'Text': str(r.text)})
with open(f'{firm}.json', 'w') as f:
json.dump(d, f)
I'm sure there's a simpler way, but thats one way.
CodePudding user response:
Here's one way to do it:
import json
import numpy as np
df=pd.DataFrame(np.array([['facebook', '15',"women tennis"], ['facebook', '20',"men basketball"], ['facebook', '30','club'],
['apple', "10","vice president"], ['apple', "100",'swimming contest']]),columns=['firm','id','text'])
for firm in set(df['firm']):
f = open(firm '.json', 'w')
f.write(json.dumps(list(df[df['firm']==firm][['id', 'text']].T.to_dict().values())))
f.close()
Output:
apple.json
[{"id": "10", "text": "vice president"}, {"id": "100", "text": "swimming contest"}]
facebook.json
[{"id": "15", "text": "women tennis"}, {"id": "20", "text": "men basketball"}, {"id": "30", "text": "club"}]