I'm working on a plotting function for the likert data from a survey and I'm trying to optimize it to be as automated as possible since I have to make quite a lot of plots and make it as user-friendly as possible, but I'm having some problems and really need help finishing this function...
These are the data:
df1<-data.frame(A=c(1,2,2,3,4,5,1,1,2,3),
B=c(4,4,2,3,4,2,1,5,2,2),
C=c(3,3,3,3,4,2,5,1,2,3),
D=c(1,2,5,5,5,4,5,5,2,3),
E=c(1,4,2,3,4,2,5,1,2,3),
dummy1=c("yes","yes","no","no","no","no","yes","no","yes","yes"),
dummy2=c("high","low","low","low","high","high","high","low","low","high"))
df1[colnames(df1)] <- lapply(df1[colnames(df1)], factor)
Columns A and B pertain to the "Technology" section of my survey, while C, D and E are in "Social".
I have transformed my data using the likertpackage and compiled them in a list to be more easily called in my function (don't know if it's the best way to go about it, I'm still quite new to R, so feel free to make suggestions even concerning this point):
vals <- colnames(df1)[1:5]
dummies <- colnames(df1)[-(1:5)]
step1 <- lapply(dummies, function(x) df1[, c(vals, x)])
step2 <- lapply(step1, function(x) split(x, x[, 6]))
names(step2) <- dummies
tbls <- unlist(step2, recursive=FALSE)
tbls<-lapply(tbls, function(x) x[(names(x) %in% names(df1[c(1:5)]))])
So far, here is the function I could come up with (with great help of user @gaut):
mynames <- sapply(names(tbls), function(x) {
paste("How do they rank? -",gsub("\\.",": ",x))
})
myfilenames <- names(tbls)
plot_likert <- function(x, myname, myfilename){
p <- plot(likert(x),
type ="bar",center=3,
group.order=names(x))
labs(x = "Theme", subtitle=paste("Number of observations:",nrow(x)))
guides(fill=guide_legend("Rank"))
ggtitle(myname)
p
I then lapply the function to get a list of plots:
list_plots <- lapply(1:length(tbls),function(i) {
plot_likert(tbls[[i]], mynames[i], myfilenames[i])
})
And then save them all as .png
sapply(1:length(list_plots), function(i) ggsave(
filename = paste0("plots ",i,".png"),
plot = list_plots[[i]],
width = 15, height = 9
))
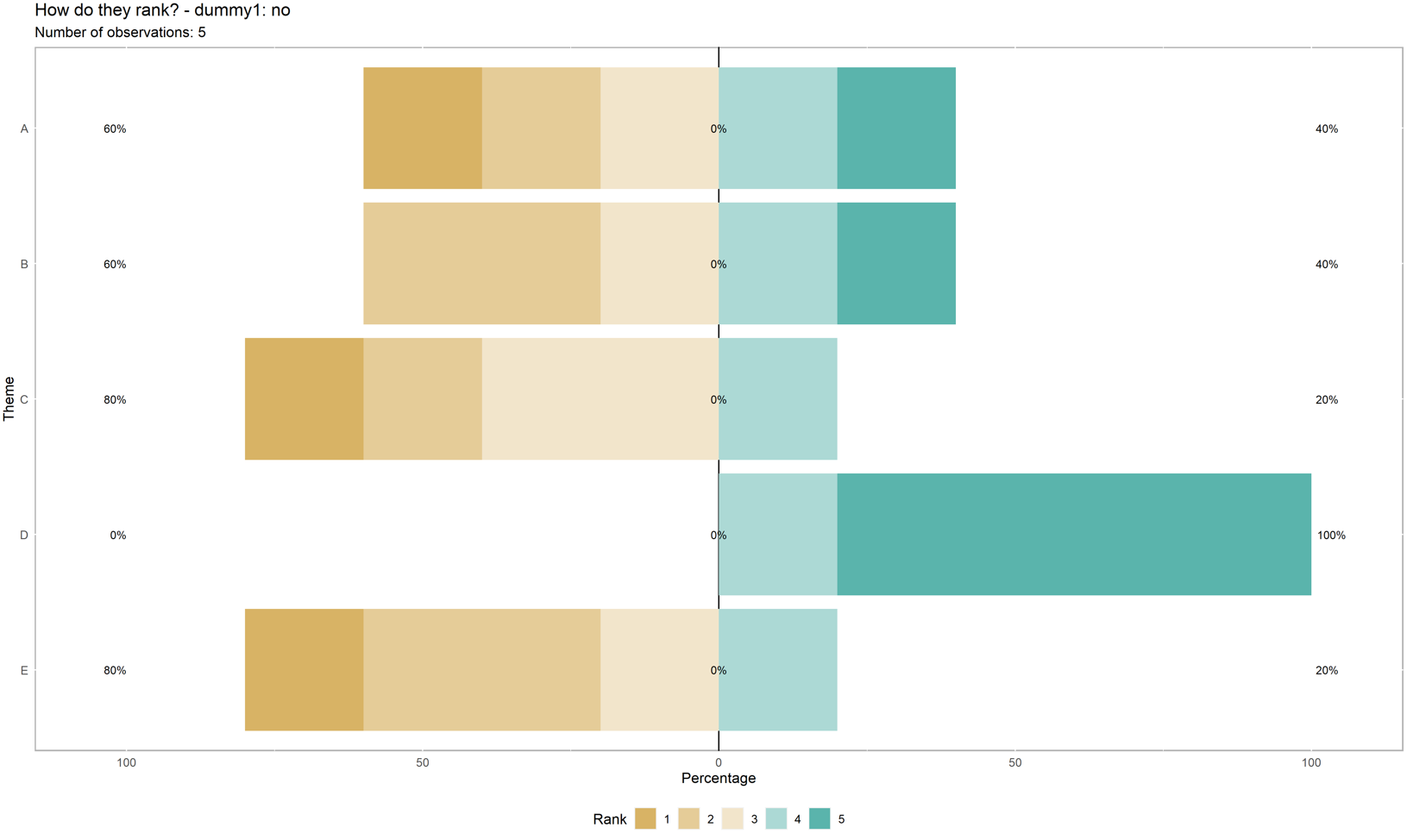
Now, there are 3 main things I want my function to do but don't really know how to approach:
1) Right now I can export all the plots in one batch, but I would also like to be able to export a single plot, for example obtaining the above graph by writing:
plot_likert(tbls$dummy1.no)
2) In my mind, my ideal plotting function would also take into account the sections of my data mentioned above, so that if I specify the section Technology only get a Likert plot considering only columns A and B, and specifying the subsample gets me the dummy. Like so:
plot_likert(section=Technology, subsample=dummy1.no)
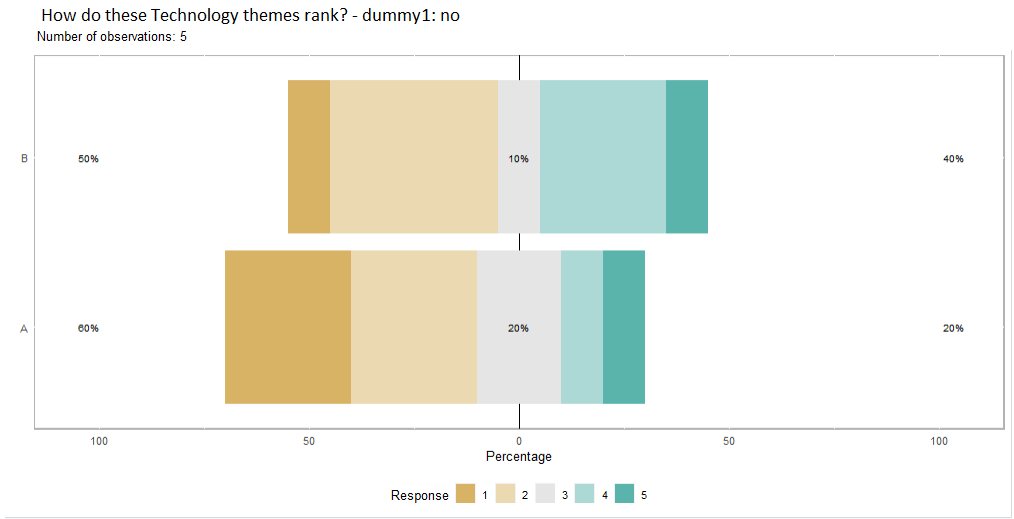
3) As you maybe have already noted, I need the titles of the plot to be fully automatic, so that by changing section or subsample they too change accordingly.
Apologies for the long/intricate question but I've been stuck on this function for quite some time and really need help finalizing it. For any further clarification/info, do not hesitate to ask!
Thank you in advance for any advice!
CodePudding user response:
There are many ways to get what you want. Essentially, you need to add a few arguments to your function.
I agree with Limey though (and of course Hadley) - generally better to have a few simple functions that do a little step and then you can collate everything in one bigger function.
df1<-data.frame(A=c(1,2,2,3,4,5,1,1,2,3),
B=c(4,4,2,3,4,2,1,5,2,2),
C=c(3,3,3,3,4,2,5,1,2,3),
D=c(1,2,5,5,5,4,5,5,2,3),
E=c(1,4,2,3,4,2,5,1,2,3),
dummy1=c("yes","yes","no","no","no","no","yes","no","yes","yes"),
dummy2=c("high","low","low","low","high","high","high","low","low","high"))
## this can be shortened
df1 <- data.frame(lapply(df1, factor))
## the rest of dummy data creation probably too, but I won't dig too much into this now
vals <- colnames(df1)[1:5]
dummies <- colnames(df1)[-(1:5)]
step1 <- lapply(dummies, function(x) df1[, c(vals, x)])
step2 <- lapply(step1, function(x) split(x, x[, 6]))
names(step2) <- dummies
tbls <- unlist(step2, recursive=FALSE)
tbls<-lapply(tbls, function(x) x[(names(x) %in% names(df1[c(1:5)]))])
library(ggplot2)
library(likert)
#> Loading required package: xtable
## no need for sapply, really!
mynames <- paste("How do they rank? -", gsub("\\.",": ",names(tbls)))
myfilenames <- names(tbls)
## defining arguments with NULL makes it possible to not specify it without giving it a value
plot_likert <- function(x, myname, myfilename, section = NULL, subsample = NULL){
## first take only the tbl of interest
if(!is.null(subsample)) x <- x[subsample]
## then filter for your section and subsample
if(!is.null(section)) x <- lapply(x, function(y) y[, section])
## you can run your lapply within the function -
## ideally make a separate funciton and call the smaller function in the bigger one
## use seq_along
lapply(seq_along(x), function(i) {
plot(likert(x[[i]]),
type ="bar",center=3,
group.order=names(x[[i]]))
labs(x = "Theme", subtitle=paste("Number of observations:",nrow(x)))
guides(fill=guide_legend("Rank"))
## programmatic title
ggtitle(names(x)[i])
})
}
## you need to pass character vectors to your arguments
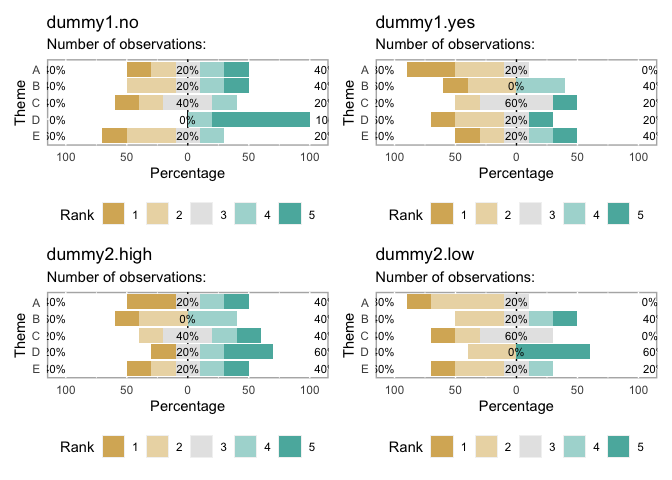
patchwork::wrap_plots(plot_likert(tbls))
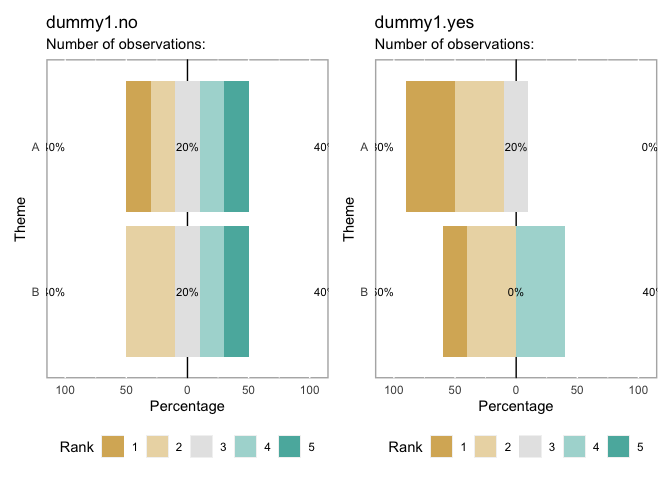
patchwork::wrap_plots(plot_likert(tbls, section = LETTERS[1:2], subsample = paste("dummy1", c("no", "yes"), sep = ".")))
Created on 2022-08-17 by the reprex package (v2.0.1)