I am working data set consisting of multiple columns with 0,1,2 value. I am trying to compute the number of times either 1 or 2 occurrences across multiple columns and finally would like to divide the total number of times for both 1 and 2.
Below is the data subset:
input
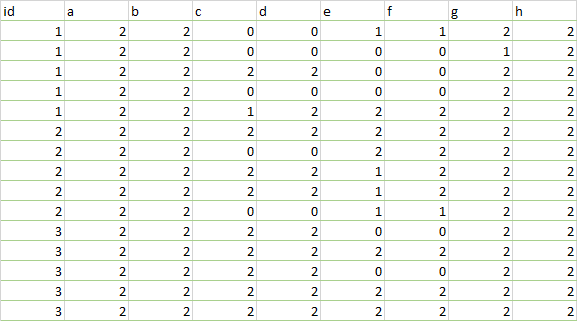
expected result

sorry for inconvenience! as i was new to this
df <- structure(list(Pool = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L,2L, 2L, 2L, 2L, 2L), a = c(2L, 2L, 2L, 2L, 2L, 2L, 2L,2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L), b = c(2L, 2L, 2L,2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), c = c(0L,0L, 2L, 0L, 1L, 2L,
0L, 2L, 2L, 0L, 2L, 2L, 2L, 2L, 2L), d = c(0L,0L, 2L, 0L, 2L,
2L, 0L, 2L, 2L, 0L, 2L, 2L, 2L, 2L, 2L), e = c(2L,2L, 2L, 0L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 2L, 0L, 2L, 2L), f = c(2L,2L, 2L,
0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L, 2L, 0L, 2L, 2L), g = c(2L,1L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L), h =c(2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L)),row.names = c(NA,15L), class = "data.frame")
If anyone could help for solution, Thank you for your time
CodePudding user response:
You could try this base R approach, though I am sure there are more elegant solutions. From your desired output, it looks like you want to calculate the proportion of 2's out of all 1's and 2's.
Data
Reproducible example data, which from your screenshot seems to be heavily favored for a value of 2
set.seed(123)
df <- data.frame(ID = rep(1:3, each = 5),
matrix(sample(0:2, 120, replace = TRUE, prob = c(20/120, 8/120, 92/120)), ncol = 8))
colnames(df)[-1] <- letters[1:8]colnames(df)[-1] <- letters[1:8]
head(df, 5)
# ID a b c d e f g h
# 1 1 2 0 1 2 2 2 2 0
# 2 1 0 2 0 2 2 2 2 0
# 3 1 2 2 2 2 2 2 2 2
# 4 1 0 2 0 2 2 2 2 2
# 5 1 1 1 2 0 0 2 2 2
Note the numbers differ from your question since the data were provided as a screenshot and this code created data at random.
Code
Splits the data frame by group then applies a function to tabulate and divide the data (a) then recombine everything into a final data frame (b). Also checks to see if there are any values of 2 at all, else returns NA.
a <- lapply(split(df[, -1], df$ID), function(x)
lapply(x, function(y) {
t <- data.frame(table(y))
if (any(t$y == 2)) {
round(t[t$y == 2, "Freq"] / sum(t[t$y %in% 1:2, "Freq"]), 1)
}
else {
NA
}
}))
b <- data.frame(ID = unique(df$ID), do.call(rbind, a))
Output:
# > b
# ID a b c d e f g h
# 1 1 0.67 0.75 0.67 1 1 1 1 1
# 2 2 1 0.75 1 1 1 1 1 0.6
# 3 3 0.8 1 1 1 1 0.67 0.8 0.8
CodePudding user response:
You could try
library(dplyr)
df %>%
group_by(id) %>%
summarise(across(everything(), ~ mean(.x[.x != 0] == 2)))