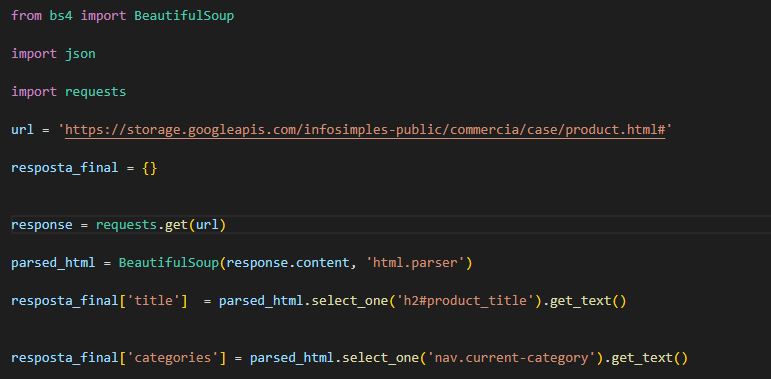
code that extracts data from the page
unexpected result .json

how to remove the '\n', as in this example?

url https://storage.googleapis.com/infosimples-public/commercia/case/product.html#
CodePudding user response:
First off, please don't use images when posting your code. It is easier for you and everyone else if you simply copy and paste it.
All you need to do is split categories by the new line character and then call str.strip to get rid of any extra whitespace
For example:
resposta_final['categories'] = [i.strip() for i in resposta_final['categories'].split("\n") if i.strip() != ""]
Add that line to the end of your script and it should be similar to your example.
CodePudding user response:
You can't use new lines inside of a json files (because you can't have a multiline string inside json), you should use lists like so {"categories":["Commercia", "Health & Care", ...]}
CodePudding user response:
What Alexander suggested works, but i think using this is better
resposta_final['categories'] = [element.get_text() for element in parsed_html.select(".current-category a")]