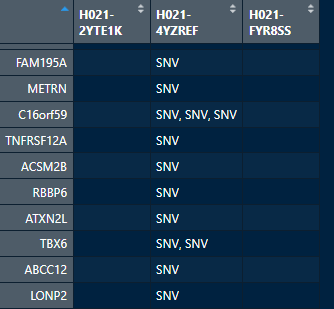
I have a data frame with multiple terms in a single column. This type of repeating terms are within the whole data frame.
I want to remove the repeating words and only keep unique values.
for a single column, i have tried this:
data$`H021-FYR8SS` <- sapply(data$`H021-FYR8SS`, function(x) paste(unique(unlist(str_split(x,", "))), collapse = "; "))
which works perfectly fine:
I want to apply this thing in the whole data frame. How do i do this?
Thanks
H021-2YTE1K H021-4YZREF H021-FYR8SS
RP1 " " "SNV, SNV, SNV" " "
NCOA2 " " "SNV" " "
RGS22 " " "SNV" " "
CSMD3 " " "SNV, SNV" " "
TNFRSF11B " " "SNV" " "
SEMA3A " " " " "insertion"
ENPP2 " " " " "deletion"
IGLV3-1 " " " " "deletion, SNV, SNV, SNV"
MTMR11 "SNV" " " " "
So, my output should look like this
H021-2YTE1K H021-4YZREF H021-FYR8SS
RP1 " " "SNV" " "
NCOA2 " " "SNV" " "
RGS22 " " "SNV" " "
CSMD3 " " "SNV" " "
TNFRSF11B " " "SNV" " "
SEMA3A " " " " "insertion"
ENPP2 " " " " "deletion"
IGLV3-1 " " " " "deletion; SNV"
MTMR11 "SNV" " " " "
CodePudding user response:
Using base:
sapply(dat,
\(y) sapply(y, \(x) paste(unique(unlist(strsplit(x,", "))), collapse = "; ")))
Using dplyr:
library(dplyr)
dat |>
rownames_to_column() |>
group_by(rowname) |>
mutate(across(everything(), ~ paste(unique(unlist(str_split(.,", "))), collapse = "; "))) |>
column_to_rownames() |>
ungroup()
Output:
H021-2YTE1K H021-4YZREF H021-FYR8SS
BRAF deletion SNV
CC2D2A insertion SNV
MRPL19 deletion; SNV
SRRM1 deletion
ZFP69B insertion
ZNF711 insertion
Data:
dat <-
structure(list(`H021-2YTE1K` = c("insertion", "deletion", "insertion", " ", " ", " "), `H021-4YZREF` = c(" ", " ", " ", "deletion", "insertion", "deletion, SNV, SNV, SNV"), `H021-FYR8SS` = c("SNV", "SNV, SNV", " ", " ", " ", " ")), row.names = c("CC2D2A", "BRAF", "ZNF711", "SRRM1", "ZFP69B", "MRPL19"), class = "data.frame")
CodePudding user response:
Here's a base R version with some explanations.
You need to apply the same operations to a number of columns. So it is useful first to create a function that does it on a single column:
fun <- function(x){
xs <- sapply(strsplit(x, ","), trimws) # fist `strsplit` by comma, then trim whitespace
# [so that the number of spaces before / after commas won't matter]
xs <- sapply(xs, unique) # keep unique elements only
sapply(xs, paste, collapse="; ") # output: paste elements, separated by ";"
}
Try it out:
fun(dat[,2])
# [1] "" "" "" "deletion" "insertion" "deletion; SNV"
You can write this function as a one-liner, which is shorter but obviously more tedious to follow:
funGolfed <- function(x) sapply(strsplit(x, ","), function(x) paste(unique(trimws(x)), collapse="; "))
# a "golfed" version, as in code golf, https://codegolf.stackexchange.com/
Or a version with pipes (possibly easier to follow):
library(magrittr)
# I am using a slightly outdated version of R - you can replace
# the magrittr pipe "%>%" by "|>"
funPiped <- function(x) x %>% strsplit(",") %>% sapply(trimws) %>% sapply(unique) %>% sapply(paste, collapse="; ")
To apply it to all columns at once:
sapply(dat, fun)
# or funGolfed, or funPiped
And to put it back to the original data frame:
dat[,] <- lapply(dat, fun)
dat
Output
> dat
H021-2YTE1K H021-4YZREF H021-FYR8SS
1 insertion SNV
2 deletion SNV
3 insertion
4 deletion
5 insertion
6 deletion; SNV
Data
dat <- structure(list(`H021-2YTE1K` = c("insertion", "deletion", "insertion", " ", " ", " "),
`H021-4YZREF` = c(" ", " ", " ", "deletion", "insertion", "deletion, SNV, SNV, SNV"),
`H021-FYR8SS` = c("SNV", "SNV, SNV", " ", " ", " ", " ")),
row.names = c(NA, -6L), class = "data.frame")