In this data.frame, I want to split the id_date into two columns id and date.
I checked previous answers and tried to use str.split but none of my trials worked.
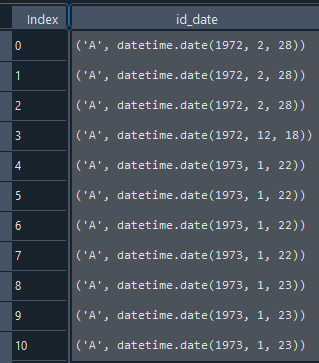
DATA
dict = {'id_date': {0: ('A', datetime.date(1972, 2, 28)), 1: ('A', datetime.date(1972, 2, 28)), 2: ('A', datetime.date(1972, 2, 28)), 3: ('A', datetime.date(1972, 12, 18)), 4: ('A', datetime.date(1973, 1, 22)), 5: ('A', datetime.date(1973, 1, 22)), 6: ('A', datetime.date(1973, 1, 22)), 7: ('A', datetime.date(1973, 1, 22)), 8: ('A', datetime.date(1973, 1, 23)), 9: ('A', datetime.date(1973, 1, 23)), 10: ('A', datetime.date(1973, 1, 23))}}
import pandas as pd
import datetime
df = pd.DataFrame.from_dict(dict)
CodePudding user response:
Use the DataFrame constructor:
out = pd.DataFrame(df['id_date'].to_list(), columns=['id', 'date'])
output:
id date
0 A 1972-02-28
1 A 1972-02-28
2 A 1972-02-28
3 A 1972-12-18
4 A 1973-01-22
5 A 1973-01-22
6 A 1973-01-22
7 A 1973-01-22
8 A 1973-01-23
9 A 1973-01-23
10 A 1973-01-23
As new columns:
df[['id', 'date']] = pd.DataFrame(df['id_date'].to_list())
output:
id_date id date
0 (A, 1972-02-28) A 1972-02-28
1 (A, 1972-02-28) A 1972-02-28
2 (A, 1972-02-28) A 1972-02-28
3 (A, 1972-12-18) A 1972-12-18
4 (A, 1973-01-22) A 1973-01-22
5 (A, 1973-01-22) A 1973-01-22
6 (A, 1973-01-22) A 1973-01-22
7 (A, 1973-01-22) A 1973-01-22
8 (A, 1973-01-23) A 1973-01-23
9 (A, 1973-01-23) A 1973-01-23
10 (A, 1973-01-23) A 1973-01-23
CodePudding user response:
Use:
df['id'] = df['id_date'].str[0]
df['date'] = df['id_date'].str[1]
OUTPUT
id_date id date
0 (A, 1972-02-28) A 1972-02-28
1 (A, 1972-02-28) A 1972-02-28
2 (A, 1972-02-28) A 1972-02-28
3 (A, 1972-12-18) A 1972-12-18
4 (A, 1973-01-22) A 1973-01-22
5 (A, 1973-01-22) A 1973-01-22
6 (A, 1973-01-22) A 1973-01-22
7 (A, 1973-01-22) A 1973-01-22
8 (A, 1973-01-23) A 1973-01-23
9 (A, 1973-01-23) A 1973-01-23
10 (A, 1973-01-23) A 1973-01-23
CodePudding user response:
You can do this :
import datetime
import pandas as pd
dict = {'id_date': {0: ('A', datetime.date(1972, 2, 28)), 1: ('A', datetime.date(1972, 2, 28)), 2: ('A', datetime.date(1972, 2, 28)), 3: ('A', datetime.date(1972, 12, 18)), 4: ('A', datetime.date(1973, 1, 22)), 5: ('A', datetime.date(1973, 1, 22)), 6: ('A', datetime.date(1973, 1, 22)), 7: ('A', datetime.date(1973, 1, 22)), 8: ('A', datetime.date(1973, 1, 23)), 9: ('A', datetime.date(1973, 1, 23)), 10: ('A', datetime.date(1973, 1, 23))}}
df = pd.DataFrame.from_dict(dict)
df['id'] = [el[0] for el in df['id_date']]
df['date'] = [el[1] for el in df['id_date']]
print(df)
output:
id_date id date
0 (A, 1972-02-28) A 1972-02-28
1 (A, 1972-02-28) A 1972-02-28
2 (A, 1972-02-28) A 1972-02-28
3 (A, 1972-12-18) A 1972-12-18
4 (A, 1973-01-22) A 1973-01-22
5 (A, 1973-01-22) A 1973-01-22
6 (A, 1973-01-22) A 1973-01-22
7 (A, 1973-01-22) A 1973-01-22
8 (A, 1973-01-23) A 1973-01-23
9 (A, 1973-01-23) A 1973-01-23
10 (A, 1973-01-23) A 1973-01-23
CodePudding user response:
Or use assign, to keep it cleaner.
df = (pd.DataFrame.from_dict(dict) .assign(id=lambda x:x['id_date'].str[0],date =lambda x:x['id_date'].str[1]))