I'm trying to web scrape a web site through python. URL = "https://www.boerse-frankfurt.de/bond/xs0216072230"
With the code below, I am getting no result, it shows this in output : {} Code is below :
import requests
url = (
"https://api.boerse-frankfurt.de/v1/data/master_data_bond?isin=XS0216072230"
)
headers = {
"X-Client-TraceId": "d87b41992f6161c09e875c525c70ffcf",
"X-Security": "d361b3c92e9c50a248e85a12849f8eee",
"Client-Date": "2022-08-25T09:07:36.196Z",
}
data = requests.get(url, headers=headers).json()
print(data)
It should print :
{ "isin": "XS0216072230", "type": { "originalValue": "25", "translations": { "de": "(Industrie-) und Bankschuldverschreibungen", "en": "Industrial and bank bonds", }, }, "market": { "originalValue": "OPEN", "translations": {"de": "Freiverkehr", "en": "Open Market"},
Any help would be appreciated, I am avoiding Selenium approach for this at the moment.
Thanks in advance.
CodePudding user response:
URL must have some data. 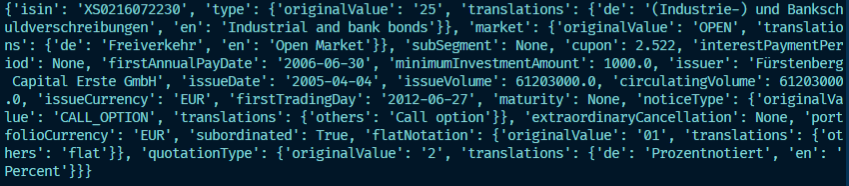
But I think you might need to update x-client-traceid,client-date, and x-security regularly