I am trying to loop through multiple folders and subfolders in Azure Blob container and read multiple xml files.
Eg: I have files in YYYY/MM/DD/HH/123.xml format
Similarly I have multiple sub folders under month, date, hours and multiple XML files at last.
My intention is to loop through all these folder and read XML files. I have tried using few Pythonic approaches which did not give me the intended result. Can you please help me with any ideas in implementing this?
import glob, os
for filename in glob.iglob('2022/08/18/08/225.xml'):
if os.path.isfile(filename): #code does not enter the for loop
print(filename)
import os
dir = '2022/08/19/08/'
r = []
for root, dirs, files in os.walk(dir): #Code not moving past this for loop, no exception
for name in files:
filepath = root os.sep name
if filepath.endswith(".xml"):
r.append(os.path.join(root, name))
return r
CodePudding user response:
The glob is a python function and it won't recognize the blob folders path directly as code is in pyspark. we have to give the path from root for this. Also, make sure to specify recursive=True in that.
For Example, I have checked above pyspark code in databricks.
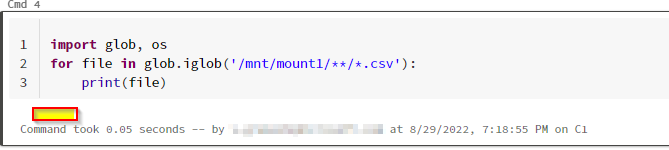
and the OS code as well.
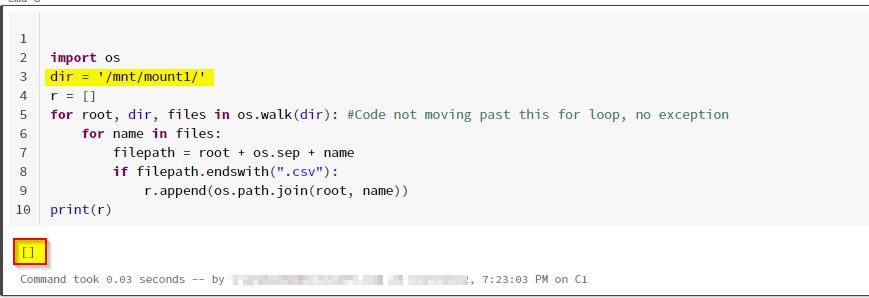
You can see I got the no result as above. Because for the above, we need to give the absolute root. it means the root folder.
glob code:
import glob, os
for file in glob.iglob('/path_from_root_to_folder/**/*.xml',recursive=True):
print(file)
For me in databricks the root to access is /dbfs and I have used csv files.
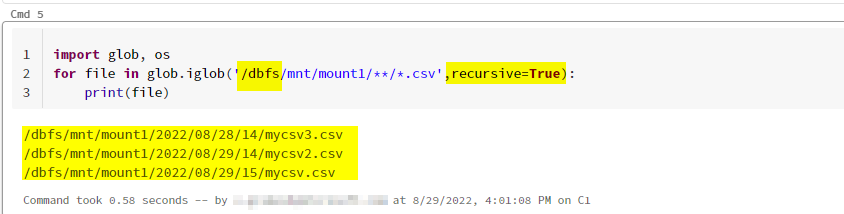
Using os:
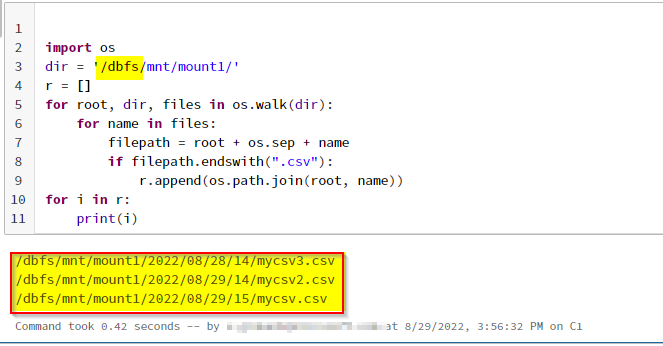
You can see my blob files are listed from folders and subfolders.
I have used databricks for my repro after mounting. Wherever you are trying this code in pyspark, make sure you are giving the root of the folder in the path. when using glob, set the recursive = True as well.
CodePudding user response:
There is an easier way to solve this problem with PySpark!
The tough part is all the files have to have the same format. In the Azure databrick's sample directory, there is a /cs100 folder that has a bunch of files that can be read in as text (line by line).
The trick is the option called "recursiveFileLookup". It will assume that the directories are created by spark. You can not mix and match files.
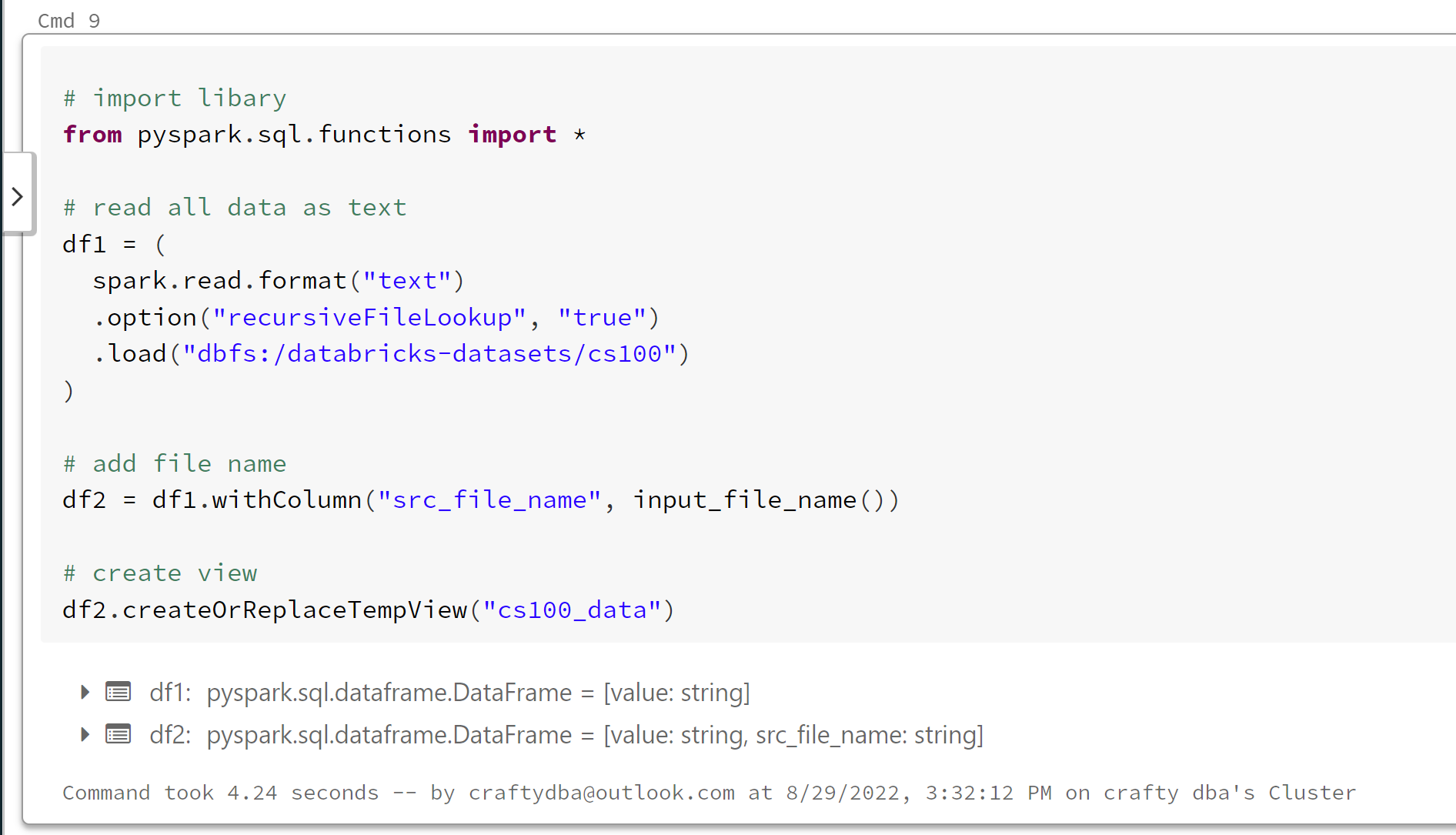
I added to the data frame the name of the input file for the dataframe. Last but not least, I converted the dataframe to a temporary view.
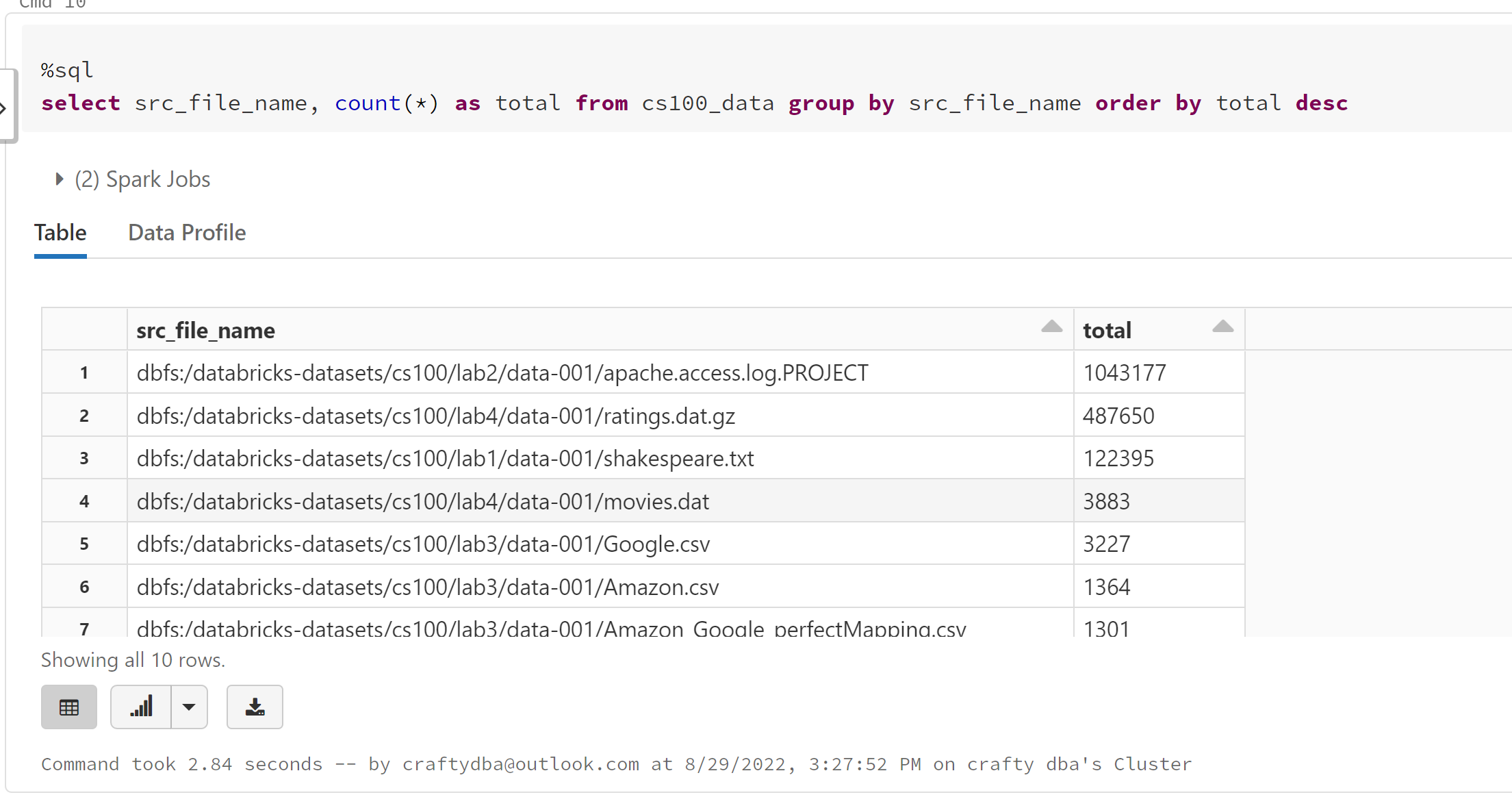
Looking at a simple aggregate query, we have 10 unique files. The biggest have a little more than 1 M records.
If you need to cherry pick files for a mixed directory, this method will not work. However, I think that is an organizational cleanup task, versus easy reading one.
Last but not least, use the correct formatter to read XML.
spark.read.format("com.databricks.spark.xml")