So I want to calculate cumulative users per day but if the users exist is previous days they will not counted.
date_key user_id
2022-01-01 001
2022-01-01 002
2022-01-02 001
2022-01-02 003
2022-01-03 002
2022-01-03 003
2022-01-04 002
2022-01-04 004
on daily basis we can get
date_key total_user
2022-01-01 2
2022-01-02 2
2022-01-03 2
2022-01-04 2
if we simply calculate cumulative we can get 2,4,6,8 for each day the goal is to get the table like this
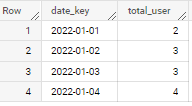
date_key total_user
2022-01-01 2
2022-01-02 3
2022-01-03 3
2022-01-04 4
im using this query to get the result, since the data is really2 huge. the query takes forever to complete.
select b.date_key,count(distinct a.user_id) total_user
from t1 a
join t1 b
on b.date_key >= a.date_key
and date_trunc(a.date_key,month) = date_trunc(b.date_key,month)
group by 1
order by 1
and yes the calculation should be on reset when the month is changing.
and btw I'm using google bigquery
CodePudding user response:
Number each user's appearance by order of date. Count only the ones seen for the first time:
with data as (
select *,
row_number() over (partition by date_trunc(date_key, month), userid
order by date_key) as rn
from T
)
select date_key,
sum(count(case when rn = 1 then 1 end)) -- or count_if(rn = 1)
over (partition by date_trunc(date_key, month)
order by date_key) as cum_monthly_users
from data
group by date_key;
Note: not [obviously] above ##1 and 2 are met - and output as expected, but also here we use HyperLogLog functions which will effectivelly address above #3
HLL functions are approximate aggregate functions. Approximate aggregation typically requires less memory than exact aggregation functions, like COUNT(DISTINCT), but also introduces statistical error. This makes HLL functions appropriate for large data streams for which linear memory usage is impractical, as well as for data that is already approximate.