I want to mask the email - the first and last character before '@' remain unmasked and the rest should be masked.
For phone number, the first and the last digit remains unmasked and the rest will be masked.
CodePudding user response:
Use regexp_replace:
Input:
from pyspark.sql import functions as F
df = spark.createDataFrame(
[(1, 'Aman', 27, '[email protected]', '9923150074'),
(2, 'Prateek', 28, '[email protected]', '8727451936'),
(3, 'Rajat', 27, '[email protected]', '9871288442')],
['Customer_Number', 'Customer_Name', 'Customer_Age', 'Email', 'Mobile']
)
Script:
df = df.withColumn('Email', F.regexp_replace('Email', '(?<!^).(?=. @)', '*'))
df = df.withColumn('Mobile', F.regexp_replace('Mobile', '(?<!^).(?!$)', '*'))
df.show()
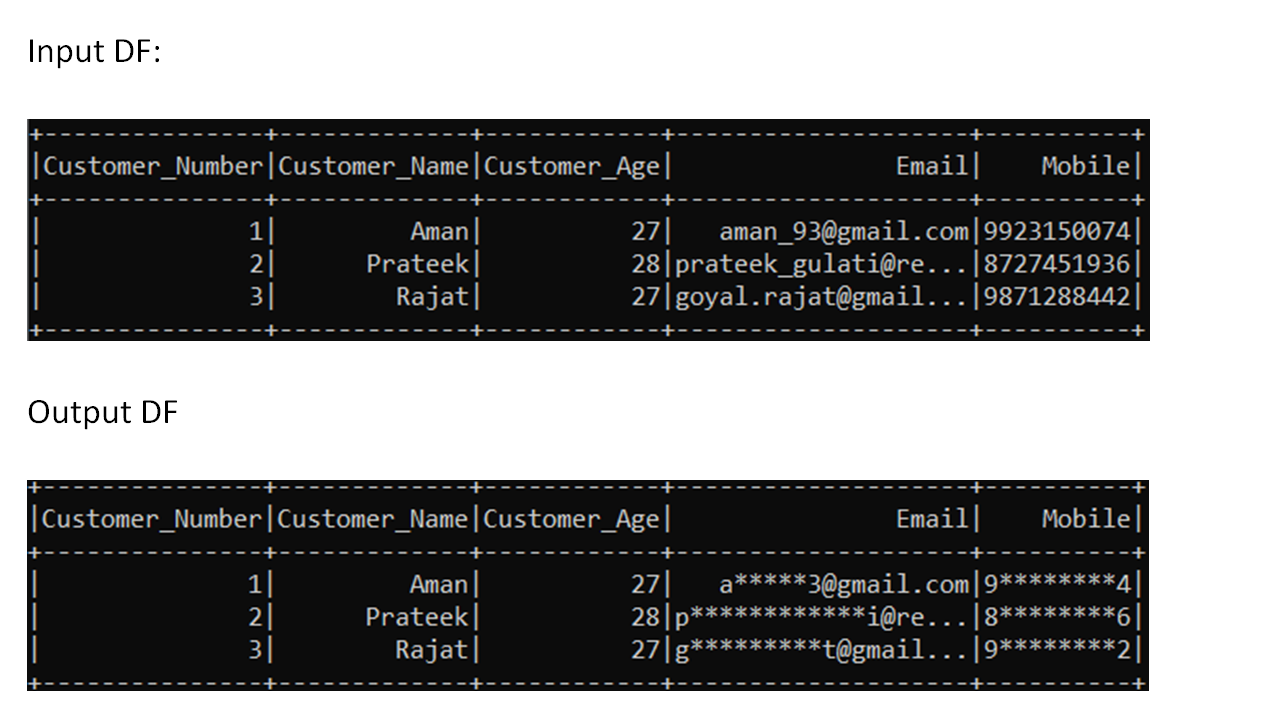
# --------------- ------------- ------------ -------------------- ----------
# |Customer_Number|Customer_Name|Customer_Age| Email| Mobile|
# --------------- ------------- ------------ -------------------- ----------
# | 1| Aman| 27| a*****[email protected]|9********4|
# | 2| Prateek| 28|p************i@re...|8********6|
# | 3| Rajat| 27|g*********t@gmail...|9********2|
# --------------- ------------- ------------ -------------------- ----------
It's enabled by regex lookarounds.
For Email, you replace every character with * when 2 conditions are satisfied:
(?<!^)means that right before this character you must not have the start of string(?=. @)means that after this character you must have at least one character followed by@symbol
For Mobile, you replace every character with * when 2 conditions are satisfied:
(?<!^)- same as above - means that right before this character you must not have the start of string(?!$)means that right after this character you must not have the end of string
CodePudding user response:
You can use a UDF for that:
from pyspark.sql.functions import udf
def mask_email(email):
at_index = email.index('@')
return email[0] "*" * (at_index-2) email[at_index-1:]
def mask_mobile(mobile):
return mobile[0] "*" * (len(mobile) - 2) mobile[-1]
mask_email_udf = udf(mask_email)
mask_mobile_udf = udf(mask_mobile)
df.withColumn("Masked_Email", mask_email_udf("Email")) \
.withColumn("Masked_Mobile", mask_mobile_udf("Mobile")) \
.show()
# --------------- ------------- ------------ -------------------- ---------- -------------------- -------------
# |Customer_Number|Customer_Name|Customer_Age| Email| Mobile| Masked_Email|Masked_Mobile|
# --------------- ------------- ------------ -------------------- ---------- -------------------- -------------
# | 1| Aman| 27| [email protected]|9923150074| a*****[email protected]| 9********4|
# | 2| Prateek| 28| [email protected]|8756325412| p*****[email protected]| 8********2|
# | 3| Rajat| 27|goyal.rajat@gmail...|8784654186|g*********t@gmail...| 8********6|
# --------------- ------------- ------------ -------------------- ---------- -------------------- -------------
It might be possible to do it directly with Spark functions but I'm not sure how.