I'm scraping a job board and two of the elements I want to extract (class_='fall-fa clock' and 'fall-fa calendar') are both under separate 'li' tags that happen to be siblings. How do I go about accessing the text of the second sibling?
Attaching a screenshot/link to the website. 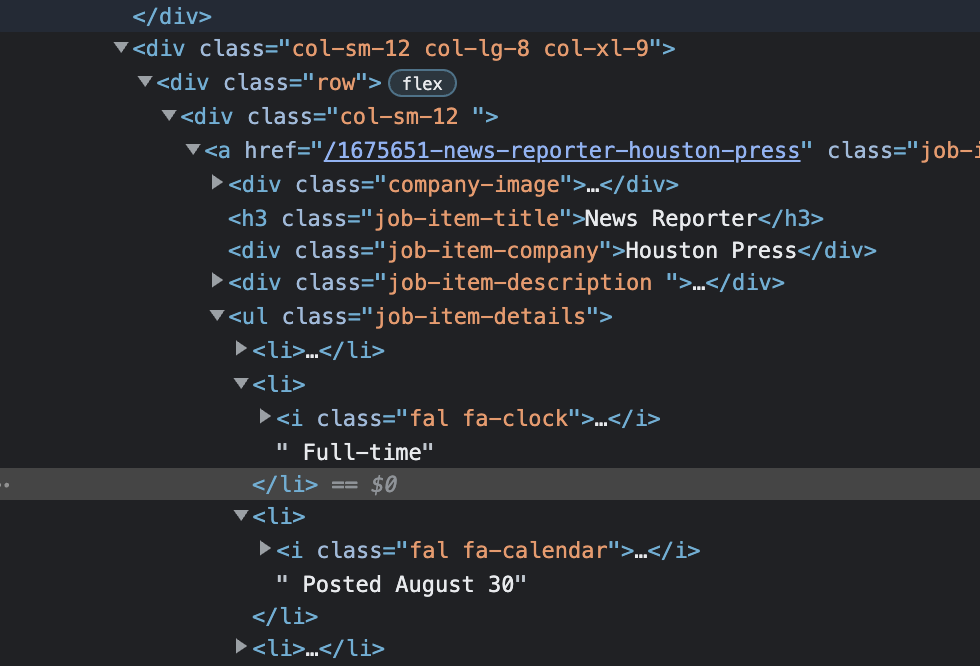
This is my code:
from bs4 import BeautifulSoup
import requests
results = requests.get('https://www.journalismjobs.com/job-listings')
soup = BeautifulSoup(results.text, 'html.parser')
jobs = soup.find_all('a', class_='job-item')
for job in jobs:
job_title = job.find('h3', class_='job-item-title').text
job_company = job.find('div', class_='job-item-company').text
job_details = job.find('ul', class_='job-item-details')
job_location = job_details.li.text.strip()
job_type = job_details.li.next_sibling # <--- stuck here!
job_desc = job.find('div', class_='job-item-description').text.strip()
CodePudding user response:
"Easy" solution would be to select all <li> tags under and use indexing:
from bs4 import BeautifulSoup
import requests
results = requests.get("https://www.journalismjobs.com/job-listings")
soup = BeautifulSoup(results.text, "html.parser")
jobs = soup.find_all("a", class_="job-item")
for job in jobs:
job_title = job.find("h3", class_="job-item-title").text
job_company = job.find("div", class_="job-item-company").text
job_details = job.find("ul", class_="job-item-details").find_all("li")
job_location = job_details[0].text.strip() # <-- first is location
job_type = job_details[1].text.strip() # <-- second is job type
job_desc = job.find("div", class_="job-item-description").text.strip()
print(job_title, job_location, job_type)
Prints:
Ida B. Wells Professor Phoenix, Arizona Full-time
Executive Editor, The Howard Center at Arizona State University Phoenix, Arizona Full-time
Executive Editor, Carnegie - Knight News21 Phoenix, Arizona Full-time
...
CodePudding user response:
you might want to try this:
from bs4 import BeautifulSoup
import requests
results = requests.get('https://www.journalismjobs.com/job-listings')
soup = BeautifulSoup(results.text, 'html.parser')
jobs = soup.find_all('a', class_='job-item')
for job in jobs:
job_title = job.find('h3', class_='job-item-title').text
job_company = job.find('div', class_='job-item-company').text
job_details = job.find('ul', class_='job-item-details')
job_location = job_details.li.text.strip()
#job_type = job_details.li.next_sibling # <--- stuck here!
job_type, job_posted = "", "" #init to empty string
if job.find('i',class_='fal fa-clock') is not None:
job_type = job.find('i',class_='fal fa-clock').parent.text.strip()
if job.find('i',class_='fal fa-calender') is not None:
job_posted = job.find('i',class_='fal fa-calender').parent.text.strip()
job_desc = job.find('div', class_='job-item-description').text.strip()
print(job_title,job_location,job_type,job_posted)
This take advantage of parser directly plus check if the item exists or not.
Enjoy!