My job has me doing some data analysis and the exported spreadsheet that is given to me (the ONLY way able to be given) has data that looks like this:
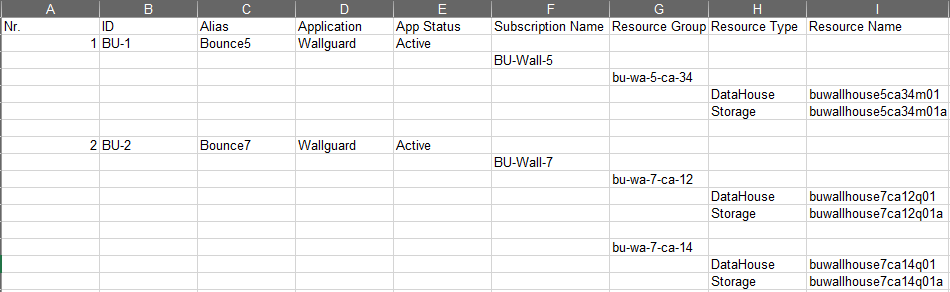
But what I need it to look like, ideally, would be something like this:

I've tried some other codes and to be honest I've made a mangled mess and got rid of it as I only succeeded in jumbling the data. I've done several other pandas projects where I was able to sort and make sense of the data, but it had the same structure and was easier to do. At this point I just dont feel I have the logical part of how to go about fixing the data. I would do it manually but it's over 48k lines. Any help you may be able to provide would be greatly appreciated.
Edit: This is what the data looks like if we 'delete blanks and shift-up'

CodePudding user response:
Try this :
import pandas as pd
df = pd.read_excel('your_excel_file.xlsx')
for i, col in enumerate(df.columns[-4:]):
if col == 'Subscription Name':
df[col] = df[col].shift(-1)
elif col == 'Resource Group':
df[col] = df[col].shift(-2)
else:
df[col] = df[col].shift(-3)
out = df.ffill().drop_duplicates().reset_index(drop=True)
>>> display(out)
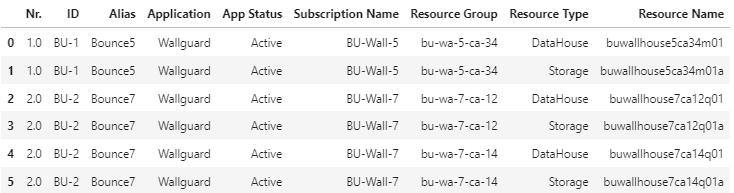
Edit :
You can also use :
out = df[df['Resource Name'].notna()].ffill()
Instead of :
out = df.ffill().drop_duplicates().reset_index(drop=True)