I am trying to scrape editor data from 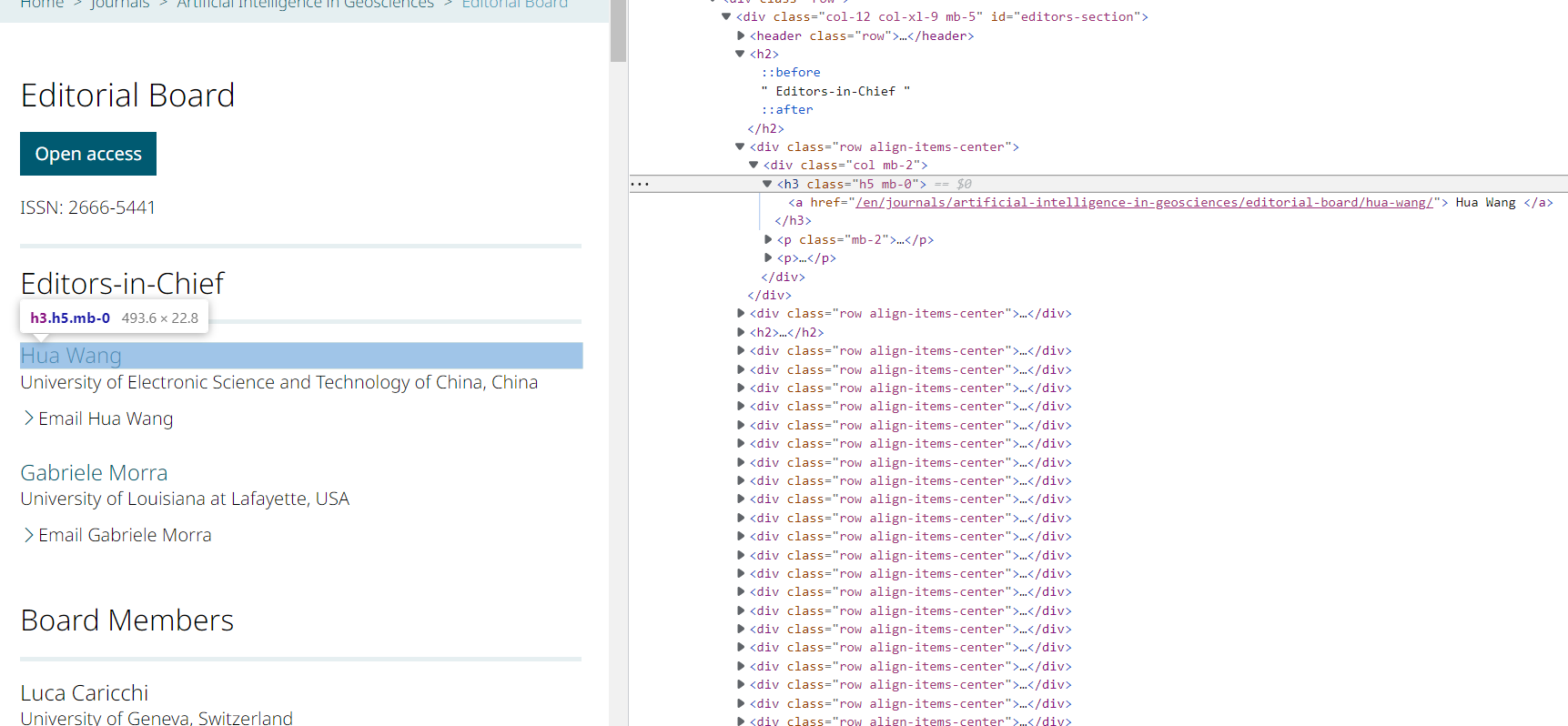 .
.
CodePudding user response:
You can use relative xpath expressions and using the following-sibling directive along with testing for adjacent role headers using the selectors root.tag attribute, you can accurately determine each persons role.
For example:
for header in response.xpath("//h2"):
role = header.xpath("./text()").get()
for sibling in header.xpath("./following-sibling::*"):
if sibling.root.tag == "h2":
break
name = sibling.xpath(".//h3/*/text()").get()
location = sibling.xpath(".//p[@class='mb-2']/text()").get()
if name and location:
yield{
"role": role.strip(),
"name": name.strip(),
"location": location.strip()
}
OUTPUT
[
{
"role": "Editors-in-Chief",
"name": "Hua Wang",
"location": "University of Electronic Science and Technology of China, China"
},
{
"role": "Editors-in-Chief",
"name": "Gabriele Morra",
"location": "University of Louisiana at Lafayette, USA"
},
{
"role": "Board Members",
"name": "Luca Caricchi",
"location": "University of Geneva, Switzerland"
},
{
"role": "Board Members",
"name": "Michael Fehler",
"location": "Massachusetts Institute of Technology, USA"
},
{
"role": "Board Members",
"name": "Peter Gerstoft",
"location": "Scripps Institution of Oceanography, USA"
},
{
"role": "Board Members",
"name": "Forrest M. Hoffman",
"location": "Oak Ridge National Laboratory, United States of America"
},
{
"role": "Board Members",
"name": "Xiangyun Hu",
"location": "China University of Geosciences, China"
},
{
"role": "Board Members",
"name": "Guangmin Hu",
"location": "University of Electronic Science and Technology of China, China"
},
{
"role": "Board Members",
"name": "Qingkai Kong",
"location": "UC Berkeley, USA"
},
{
"role": "Board Members",
"name": "Yuemin Li",
"location": "University of Electronic Science and Technology of China, China"
},
{
"role": "Board Members",
"name": "Hongjun Lin",
"location": "Zhejiang Normal University, China"
},
{
"role": "Board Members",
"name": "Aldo Lipani",
"location": "University College London, United Kingdom"
},
{
"role": "Board Members",
"name": "Zhigang Peng",
"location": "Georgia Institute of Technology, USA"
},
{
"role": "Board Members",
"name": "Piero Poli",
"location": "Grenoble Alpes University, France"
},
{
"role": "Board Members",
"name": "Kunfeng Qiu",
"location": "China University of Geoscience, China"
},
{
"role": "Board Members",
"name": "Calogero Schillaci",
"location": "JRC European Commission, Italy"
},
{
"role": "Board Members",
"name": "Hosein Shahnas",
"location": "University of Toronto, Canada"
},
{
"role": "Board Members",
"name": "Byung-Dal So",
"location": "Kangwon National University, South Korea"
},
{
"role": "Board Members",
"name": "Rui Wang",
"location": "China University of Geoscience, China"
},
{
"role": "Board Members",
"name": "Yong Wang",
"location": "East Carolina University, USA"
},
{
"role": "Board Members",
"name": "Zhiguo Wang",
"location": "Xi'an Jiaotong University, China"
},
{
"role": "Board Members",
"name": "Jun Xia",
"location": "Wuhan University, China"
},
{
"role": "Board Members",
"name": "Lizhi Xiao",
"location": "China University of Petroleum(Beijing), China"
},
{
"role": "Board Members",
"name": "Chicheng Xu",
"location": "Aramco Services Company, USA"
},
{
"role": "Board Members",
"name": "Zhibing Yang",
"location": "Wuhan University, China"
},
{
"role": "Board Members",
"name": "Nana Yoshimitsu",
"location": "Kyoto University, Japan"
},
{
"role": "Board Members",
"name": "Hongyan Zhang",
"location": "Wuhan University, China"
}
]
CodePudding user response:
At first, iterate all the div elements then use relative CSS Selectors as follows:
import scrapy
class TestSpider(scrapy.Spider):
name = 'text'
allowed_domains = ['keaipublishing.com']
start_urls = ['https://www.keaipublishing.com/en/journals/artificial-intelligence-in-geosciences/editorial-board/']
def parse(self, response):
for div in response.css("#editors-section>div.row.align-items-center"):
name=''.join([x.get().strip() for x in div.css('h3.h5.mb-0 a::text') div.css('h3.h5.mb-0 span::text')])
org=''.join([x.get().strip() for x in div.css('p.mb-2::text')])
yield {
'Role':div.xpath('normalize-space(//*[@]/../h2/text())').get(),
'Name':name,
'Organization': org,
}
Output:
{'Role': 'Editors-in-Chief', 'Name': 'Hua Wang', 'Organization': 'University of Electronic Science and Technology of China, China'}
2022-09-03 02:47:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.keaipublishing.com/en/journals/artificial-intelligence-in-geosciences/editorial-board/>
{'Role': 'Editors-in-Chief', 'Name': 'Gabriele Morra', 'Organization': 'University of Louisiana at Lafayette, USA'}2022-09-03 02:47:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.keaipublishing.com/en/journals/artificial-intelligence-in-geosciences/editorial-board/>
{'Role': 'Editors-in-Chief', 'Name': 'Luca Caricchi', 'Organization': 'University of Geneva, Switzerland'}
2022-09-03 02:47:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.keaipublishing.com/en/journals/artificial-intelligence-in-geosciences/editorial-board/>
{'Role': 'Editors-in-Chief', 'Name': 'Michael Fehler', 'Organization': 'Massachusetts Institute of Technology, USA'}