I am using org.apache.pdfbox.text.PDFTextStripper version 2.0.26. It works good for most PDFs. But It cannot extract text correctly from Linearized PDF:

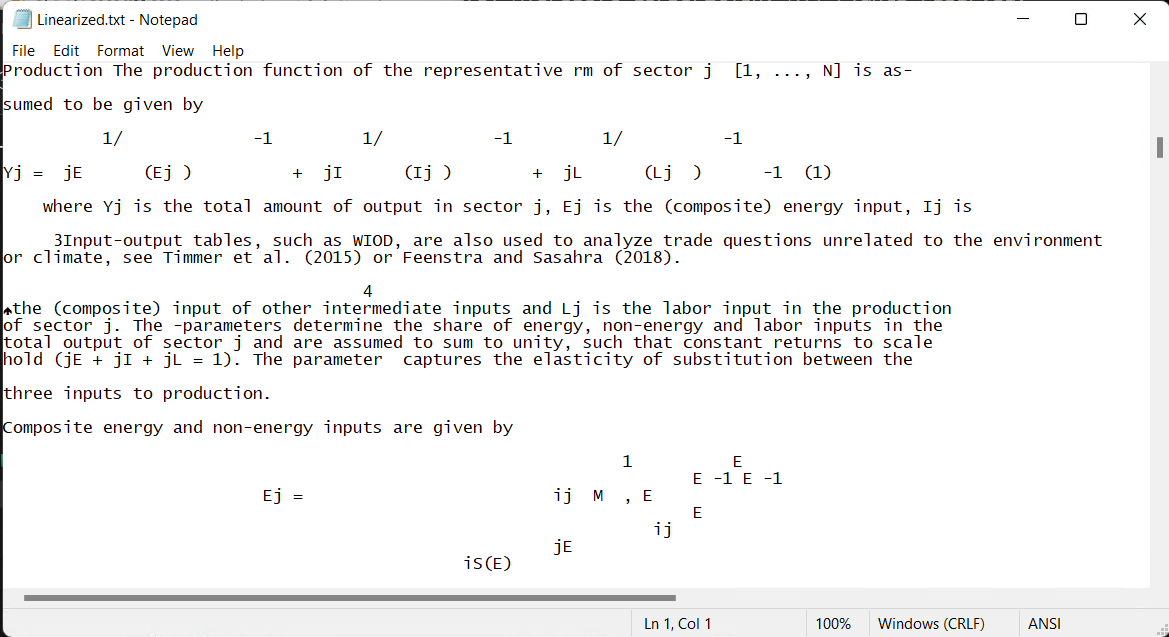
Here we can see the infty isolated svg formula from the pdf and its OCR extracted characters Yj= γEj 1/θ(Ej)θ−1.... which is meaningless for this type of reversal. A copy of math tables or formulas as images is usually the best possible solution otherwise the result is highly likely to be corrupted. Note how some braces are recognized but not some critical ones.
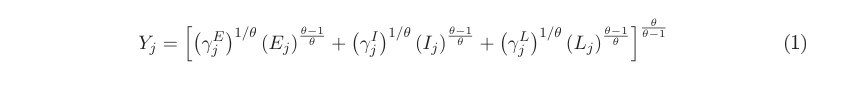

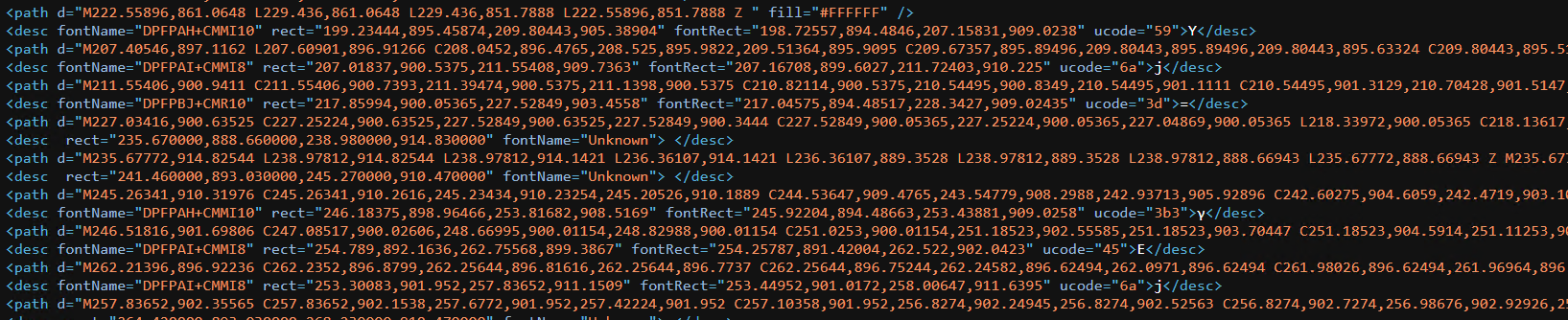
We can see why that will happen by looking at the outline of that area, looks like CMEX10 is one of the worst defined as text. θ γLj 1/θ(Lj)θ−1
