I am beginner to scala. I tried scala REPL window in intellij.
I have a sample df and trying to test udf function not builtin for understanding.
df:
scala> import org.apache.spark.sql.SparkSession
val spark: SparkSession = SparkSession.builder.appName("elephant").config("spark.master", "local[*]").getOrCreate()
val df = spark.createDataFrame(Seq(("A",1),("B",2),("C",3))).toDF("Letter", "Number")
df.show()
output:
|Letter|Number|
------ ------
| A| 1|
| B| 2|
| C| 3|
------ ------
udf for dataframe filter:
scala> def kill_4(n: String) : Boolean = {
| if (n =="A"){ true} else {false}} // please validate if its correct ???
I tried
df.withColumn("new_col", kill_4(col("Letter"))).show() // please tell correct way???
error
error: type mismatch
Second: I tried on a col list:
scala> val lst = df.select("Letter").collect().map(_(0)).toList
val res56: List[Any] = List(A, B, C)
lst.filter(kill_4) //please suggest ???
error mismatch type
CodePudding user response:
You can register udf and use it in code as follows:
import org.apache.spark.sql.functions.col
def kill_4(n: String) : Boolean = {
if (n =="A"){ true } else {false}
}
val kill_udf = udf((x: String) => kill_4(x))
df.select(col("Letter"),col("Number")
kill_udf(col("Letter")).as("Kill_4") ).show(false)
CodePudding user response:
Please look at the databricks documentation on scala user defined funcitons.
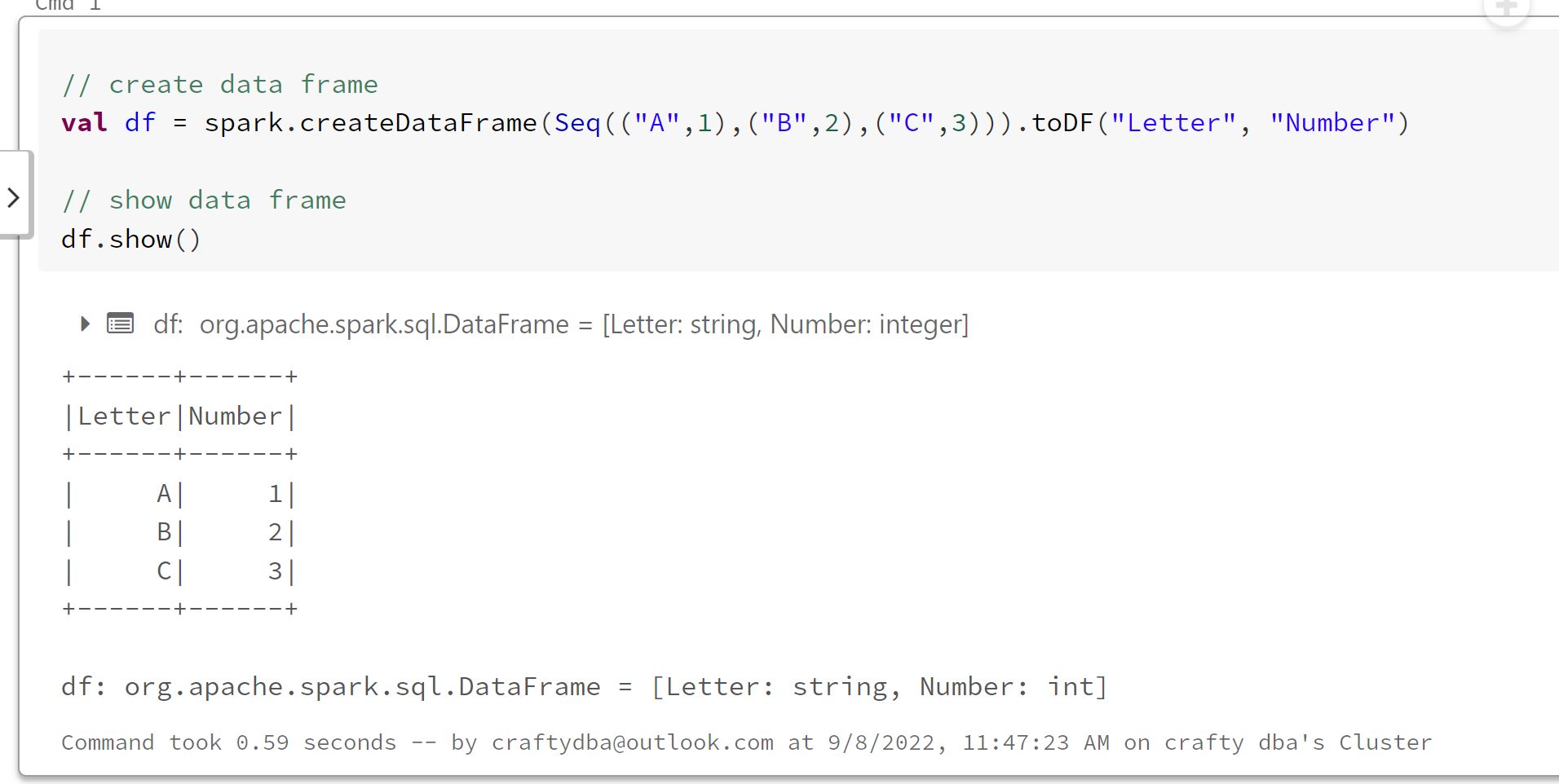
You do not need the spark session to create a dataframe. I removed that code.
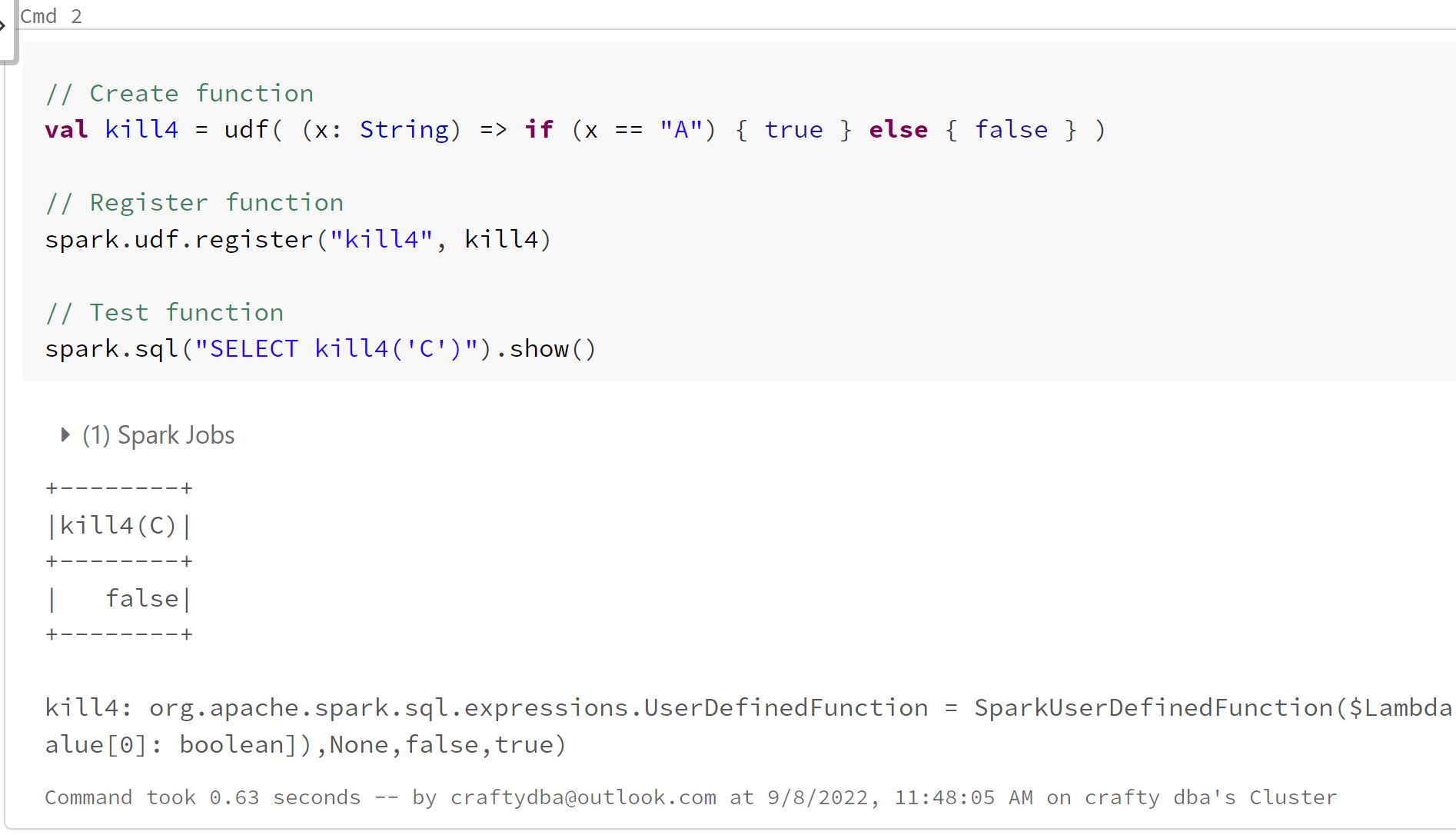
Your function had a couple bugs. Since it is very small, I created a inline one. The udf() call allows the function to be used with dataframes. The call to register allows it to be used with Spark SQL.
A quick SQL statement shows the function works.
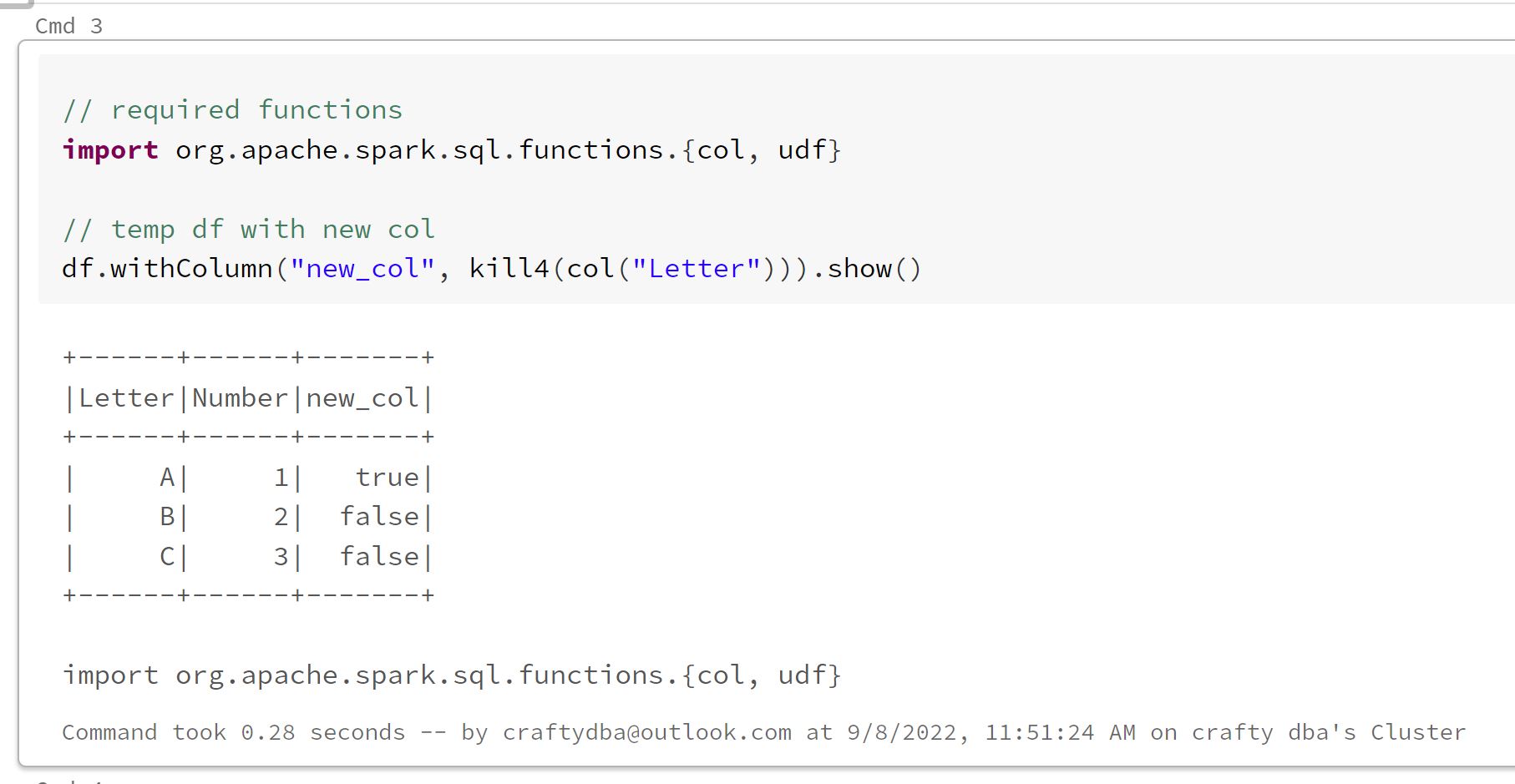
Last but not least, we need the udf() and col() functions for the last statement to work.
In short, these three snippets solve your problem.