Starting from a dataframe df I would like to groupby and sum per each category in a specific column and create a new column per each category (see below example with desired output). As an example given the dataframe df
data = {"ID": ["111", "111","111" , "2A2","3B3","4C4","5D5","6E6",],
"category": ["A", "B", "A","A","B","B","C","C",],
"length": [1,2,4,1,2,2,1,3],}
df = pd.DataFrame(data)
I would like to obtain the original dataframe df with the additional columns A, B ,C (one new column per each unique attribute in the column "category") grouped by "ID"
I've checked some similar answers so far but I could not solve the issue.
This is one approach that I've followed without getting the desired output:
grouped_multiple = df.groupby(['ID','material']).agg({'length': [np.sum, np.sum, np.sum]})
grouped_multiple.columns = ["A", "B", "C"]
grouped_multiple = grouped_multiple.reset_index()
print(grouped_multiple)
which outputs:
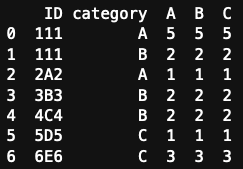
However my desidered output would look like
ID category A B C
0 111 A 5 2 0
1 2A2 A 1 0 0
2 3B3 B 0 2 0
3 4C4 B 0 2 0
4 5D5 C 0 0 1
5 6E6 C 0 0 3
Every element in the category column is grouped by the ID and category and then summed, then the columns are created for every unique value in the category column.
Thanks for any help!
Edit: The solution is working correctly: There are three points which I'd like to extend. First transform on the fly the names of the new columns,
say
ID category Custom_name_A Custom_name_B Custom_name_C
0 111 A 5 2 0
1 2A2 A 1 0 0
2 3B3 B 0 2 0
3 4C4 B 0 2 0
4 5D5 C 0 0 1
5 6E6 C 0 0 3
Second, if I have an additional column with some years/decade
data = {"ID": ["111", "111","111" , "2A2","3B3","4C4","5D5","6E6",],
"category": ["A", "B", "A","A","B","B","C","B",],
"date": ["2020", "2010","2010", "1990", "1990","2010","2020","1990"]
"length": [1,2,4,1,2,2,1,3],}
I would like to see the following desired output: (CN = custom name, meaning a whatever string I need)
{kind=link}
Lastly: I would like that this output is reflected in the original dataframe (because there are other columns which are not used by I would like them to be in this final group by) Many thanks!
CodePudding user response:
df.groupby(['ID', 'category'])['length'].sum().unstack().fillna(0)
Output:
category A B C
ID
111 5.0 2.0 0.0
2A2 1.0 0.0 0.0
3B3 0.0 2.0 0.0
4C4 0.0 2.0 0.0
5D5 0.0 0.0 1.0
6E6 0.0 0.0 3.0
By the adding rename() you can give manual custom column names
df = df.groupby(['ID', 'category'])['length'].sum().unstack().fillna(0).rename(columns={'A':'Cat_A', 'B':'Cat_B'})
df.columns
Index(['Cat_A', 'Cat_B', 'C'], dtype='object', name='category')
UPDATE:
here I have given d name to your second time provided data
d.groupby(['ID','category','date'])['length'].sum().unstack().fillna(0).reset_index('category').groupby(['ID','category'])['1990','2010','2020'].sum().unstack().fillna(0)
Output:
date 1990 2010 2020
category A B C A B C A B C
ID
111 0.0 0.0 0.0 4.0 2.0 0.0 1.0 0.0 0.0
2A2 1.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3B3 0.0 2.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
4C4 0.0 0.0 0.0 0.0 2.0 0.0 0.0 0.0 0.0
5D5 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.0
6E6 0.0 3.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Furthermore, your can clean this both dfs and concat, according to your need.
CodePudding user response:
IIUC, a pivot_table should do the job -
df.pivot_table(values="length", index="ID", columns="category", aggfunc='sum').fillna(0).astype(int)
Output
category A B C
ID
111 5 2 0
2A2 1 0 0
3B3 0 2 0
4C4 0 2 0
5D5 0 0 1
6E6 0 0 3