The data frame has more than a million rows. Here's a small sample:
df_dict = pd.DataFrame({'Query_ID': {692260: 24055,
887923: 9730,
10803: 24055,
885373: 9730,
675813: 9730,
238990: 24055,
930097: 33748,
796353: 9730,
296925: 653,
521574: 24055,
760389: 653,
57514: 23674,
512747: 653,
681778: 9730,
143410: 24055,
824324: 40359,
653270: 9730,
820505: 24055,
178048: 40759,
390705: 9730},
'Position': {692260: 7.0,
887923: 9.5,
10803: 1.0,
885373: 9.5,
675813: 7.0,
238990: 2.0,
930097: 10.0,
796353: 8.571428571428571,
296925: 3.0,
521574: 5.0,
760389: 8.0,
57514: 1.0,
512747: 5.0,
681778: 7.0,
143410: 1.0,
824324: 9.0,
653270: 7.0,
820505: 9.0,
178048: 2.0,
390705: 4.0},
'Impressions': {692260: 1,
887923: 2,
10803: 1,
885373: 2,
675813: 1,
238990: 1,
930097: 1,
796353: 21,
296925: 1,
521574: 1,
760389: 1,
57514: 1,
512747: 1,
681778: 2,
143410: 1,
824324: 1,
653270: 6,
820505: 1,
178048: 1,
390705: 1}})
df_dict
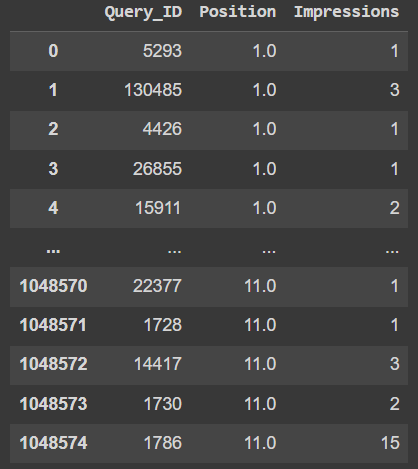
Query_ID are unique and thousands among millions of rows. Positions are a few thousand unique FLOATS. Impressions are thousands of unique int. For every Query_ID, I need to find the percentage change in total sum of impressions as the Query_ID changes its position.
Process (maybe): Percentage increase/decrease in TOTAL no. of impressions: For that unique_ID: (Total number of impressions in position 1) * x/100 = (Total number of impressions in position 2)
x = ((Total number of impressions in position 2) * 100)/(Total number of impressions in position 1)
Example solution:
function(Query_ID, Position_1, Position_2):
...
...
return Percentage_Change_in_Impresssions
Input:
function(9730, 7, 4)
Output:
-23%
Can someone please at least point me in the right direction?
CodePudding user response:
If I understood your question right, your sample data is not the best to start with. I had to do some changes on it, for the results to make sense.
If I understand it well, what you have is a limited number of Query_ID which defines the objects that move along Positions values. It might happen that the number of position values are not the same for every ID. And what you want to do is to compute the percentage change of the impressions between two consecutive positions per ID, for the whole Dataset.
If that is what you need to do, here is the how to (otherwise go to the end of my reply):
Considering that you have a couple of million of rows of data, you need to avoid iteration row per row, so better to use the vectorized operations of pandas and numpy.
My approach would be to sort the elements (if they are not already sorted) by ID and position tag, and then apply a shift on the impressions column to get its previous value. The compute of the percentage of change then becomes trivial.
Of course, then you will verify that you are not mixing impressions of two different Query IDs. That can easily be solved by applying a mask to check if the IDs of the previous impression correspond to the ID you have on the current row.
Here the code for it:
df_dict = pd.DataFrame({'Query_ID': {692260: 15478,
887923: 15478,
10803: 15478,
885373: 1819,
675813: 622,
238990: 1060,
930097: 1819,
796353: 622,
296925: 15478,
521574: 15478,
760389: 1819,
57514: 15478,
512747: 1819,
681778: 622,
143410: 1060,
824324: 622,
653270: 15478,
820505: 622,
178048: 1060,
390705: 1060},
'Position': {692260: 7.0,
887923: 9.5,
10803: 1.0,
885373: 9.5,
675813: 7.0,
238990: 2.0,
930097: 10.0,
796353: 8.571428571428571,
296925: 3.0,
521574: 5.0,
760389: 8.0,
57514: 1.0,
512747: 5.0,
681778: 7.0,
143410: 1.0,
824324: 9.0,
653270: 7.0,
820505: 9.0,
178048: 2.0,
390705: 4.0},
'Impressions': {692260: 1,
887923: 2,
10803: 1,
885373: 2,
675813: 1,
238990: 1,
930097: 1,
796353: 21,
296925: 1,
521574: 1,
760389: 1,
57514: 1,
512747: 1,
681778: 2,
143410: 1,
824324: 1,
653270: 6,
820505: 1,
178048: 1,
390705: 1}})
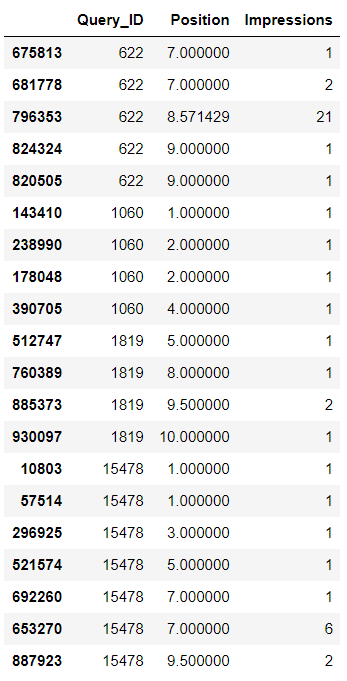
Then you will need to sort them, this will be the most expensive operation on the processing:
df_dict.sort_values(['Query_ID', 'Position'], inplace=True)
df_dict
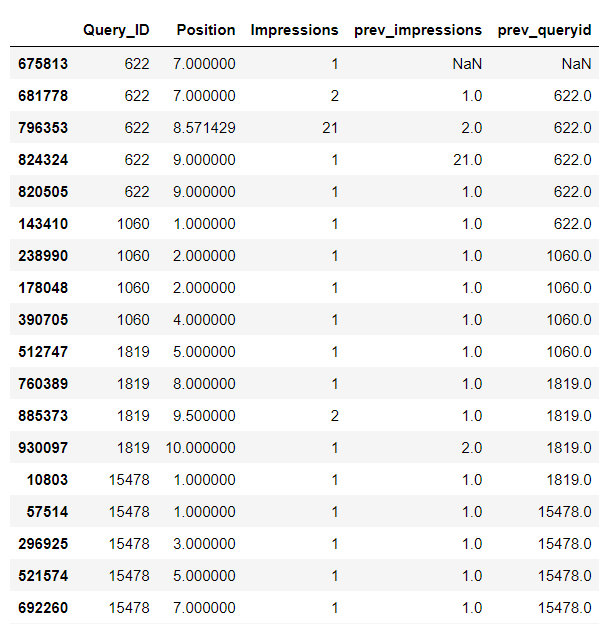
To get the previous values of Impressions and Query IDs:
df_dict['prev_impressions'] = df_dict['Impressions'].shift( 1)
df_dict['prev_queryid'] = df_dict['Query_ID'].shift( 1)
df_dict
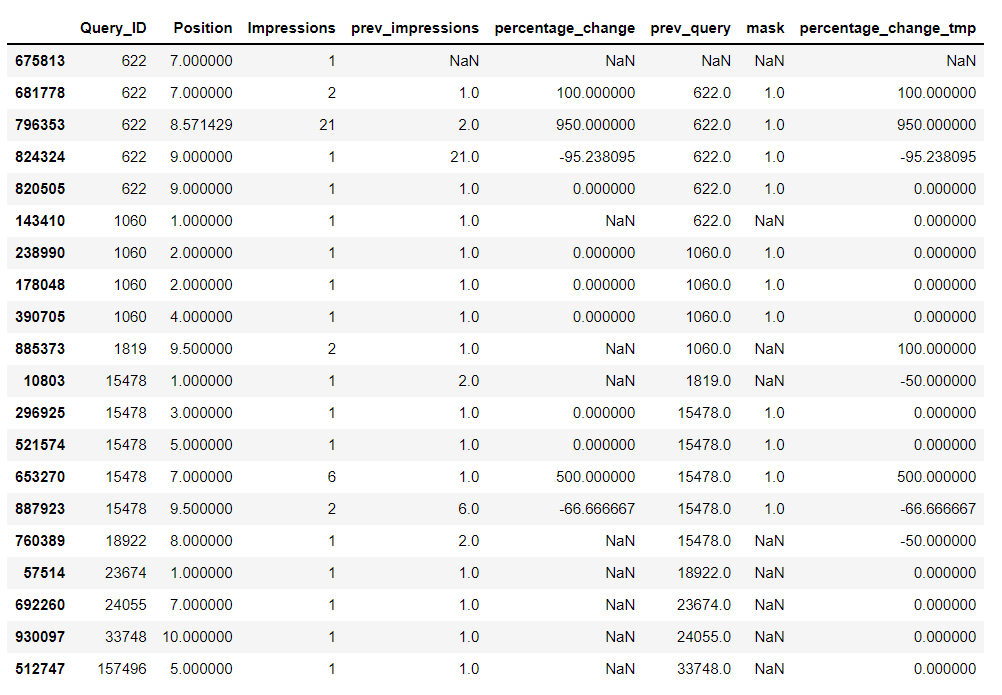
Compute the percentage change:
df_dict['percentage_change_tmp'] = 100*(df_dict['Impressions'] - df_dict['prev_impressions']) / df_dict['prev_impressions']
df_dict
Be aware that some of this percentage changes are wrong (because the previous impression value doesn't correspond to the same query ID), so just apply a mask to clean them:
df_dict['mask'] = np.where(df_dict['Query_ID'] == df_dict['prev_queryid'], 1, np.nan)
df_dict['percentage_change'] = df_dict['percentage_change_tmp'] * df_dict['mask']
df_dict
Last cleaning touch to your data frame:
df_dict = df_dict[['Query_ID', 'Position', 'Impressions', 'prev_impressions', 'percentage_change']]
df_dict
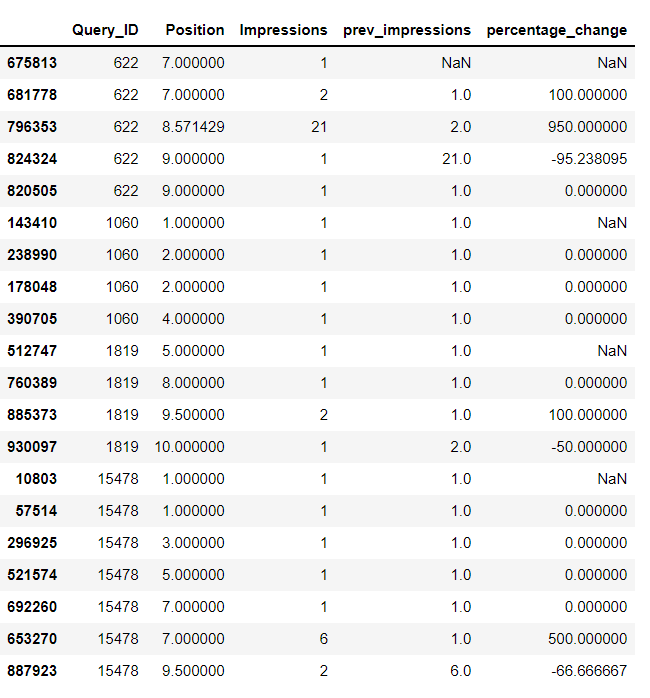
Hope this will be useful. Otherwise, if what you need is just a function that returns the percentage of change for a given tuple (Query_ID, position_1, position_2), then you can just use the .loc method in pandas and add the dataframe to its input parameters:
def percentage_change(query_id, position_1, position_2, df):
impression_1 = df.loc[(df_dict['Query_ID'] == query_id) & (df['Position'] == position_1), 'Impressions'].values[0]
impression_2 = df.loc[(df_dict['Query_ID'] == query_id) & (df['Position'] == position_2), 'Impressions'].values[0]
return 100 * (impression_2 - impression_1) / impression_1
CodePudding user response:
Made this, works.
def percentage_change(df, query, pos_1, pos_2):
'''
df = The data frame to be used.
query = Search keyword.
pos_1 = First position of the keyword.
pos_2 = Second position of the keyword.
Returns: Percentage increase or decrease in total number of impressions after change in position.
'''
df = df
query = query
pos_1 = df['Impressions'].loc[(df['Query_ID'] == query) & (df['Position'] == pos_1)].sum()
print('Impressions at first location: ' str(pos_1))
pos_2 = df['Impressions'].loc[(df['Query_ID'] == query) & (df['Position'] == pos_2)].sum()
print('Impressions at second location: ' str(pos_2))
x = print(str(round(((pos_2*100)/pos_1), 2) - 100) '%')
return x