In Apache Beam's Spark 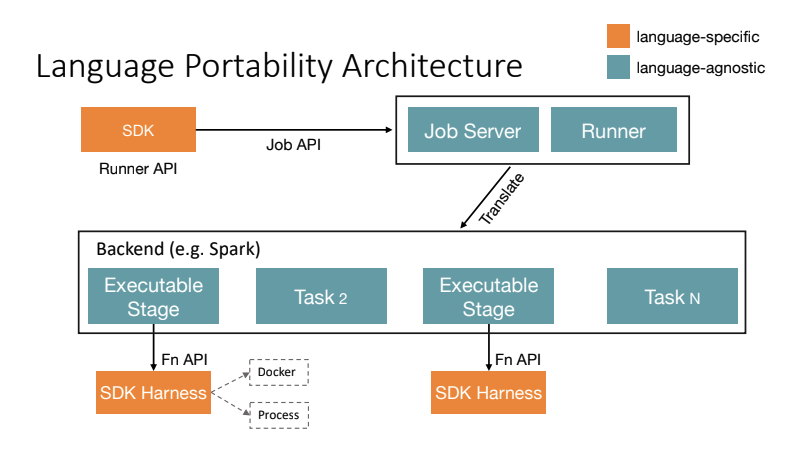 (it's taken form my talk for Beam Summit 2020 about running cross-language pipelines on Beam).
(it's taken form my talk for Beam Summit 2020 about running cross-language pipelines on Beam).
For example, if you run your Beam pipeline with Beam Portable Runner on Spark cluster, then Beam Portable Spark Runner will translate your job into a normal Spark job and then submit/run it on ordinary Spark cluster. So, it will use driver/executors of your Spark cluster (as usually).
As you can see from this picture, the Docker container is using just as part of SDK Harness to execute DoFn code independently from the "main" language of your pipeline (for example, run some Python code as a part of Java pipeline).
The only requirement, iirc, is that your Spark executors should be have installed Docker to run Docker container(s). Also, you can pre-fetch Beam SDK Docker images on Spark executors nodes to avoid it while running your job for the first time.
Alternative solution, that Beam Portability provides for portable pipelines, could be to execute SDK Harness as just a normal system process. In this case, you need to specify environment_type="PROCESS" and provide a path to executable file (that obviously has to be installed on all executor nodes).