Completely lost on how to do the second ask in this question:
- Print the name and grade percentage of the student with the highest total of points.
- Find the average score of each assignment.
- Find and apply a curve to each student's total score, such that the best student has 100% of the total points.
Starting Code:
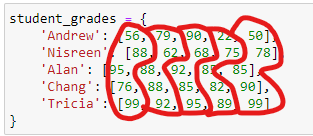
# student_grades contains scores (out of 100) for 5 assignments
student_grades = {
'Andrew': [56, 79, 90, 22, 50],
'Nisreen': [88, 62, 68, 75, 78],
'Alan': [95, 88, 92, 85, 85],
'Chang': [76, 88, 85, 82, 90],
'Tricia': [99, 92, 95, 89, 99]
}
CodePudding user response:
import pandas as pd
student_grades = {
'Andrew': [56, 79, 90, 22, 50],
'Nisreen': [88, 62, 68, 75, 78],
'Alan': [95, 88, 92, 85, 85],
'Chang': [76, 88, 85, 82, 90],
'Tricia': [99, 92, 95, 89, 99]
}
df = pd.DataFrame(student_grades)
df['average score'] = df.mean(axis=1)
print(df)
Output:
Andrew Nisreen Alan Chang Tricia average score
0 56 88 95 76 99 82.8
1 79 62 88 88 92 81.8
2 90 68 92 85 95 86.0
3 22 75 85 82 89 70.6
4 50 78 85 90 99 80.4
CodePudding user response:
Here is a solution with pure python
print([sum(assignment) / len(assignment) for assignment in zip(*student_grades.values())])
Basically we are trying to do what I outline in this picture - group the scores vertically so that we can find the average. Whenever you want to group across many lists, the zip function comes in handy