I have dataframe df that looks like this
Lvl Distance iMap Grp
0 37 63 A3 1
1 37 59 A9 1
2 37 54 A3 2
3 37 48 A4 2
...
190 37 27 A3 1
191 37 20 A3 4
I have 2 filters that I am trying to combine with "OR"
The first is m1
m1 = df[(df["Distance"]<55)].groupby('Grp').cumcount().eq(0)
you notice that m1 index starts with 2 (not 0)
>>> m1
2 True
3 False
4 False
...
187 True
188 False
189 False
190 False
191 False
also the 2nd filter
m2 = df['Distance'].gt(55)
you notice that m2 index starts with 0
>>> m2
0 True
1 True
2 False
3 False
4 False
...
187 False
188 False
189 False
190 False
191 False
When I try to combine both filters
df[m1 | m2]
and results
Lvl Distance iMap Grp
2 37 54 A3 2
19 37 41 A4 3
74 37 36 A3 1
187 37 29 A3 4
you can see that the first 2 records were not selected although their value is True in m2
but that value does not exist in m1
any idea how to fix this? so if any index is True it shows
CodePudding user response:
IMO, m1 construction is incomplete. You need to create a mask that has the same length as df. To do that, one method is, via the isin() method, check if the indexes of the rows flagged as True in m1 exist in df.index. That way, you can make the True values in m1 correspond to df.index.
# first create groups as before
m1 = df[df['Distance']<55].groupby('Grp').cumcount().eq(0)
# filter for the index of the values flagged True in `m1` and
# flag the rows of these indexes as True
m1 = df.index.isin(m1.index[m1])
# m2 construction as before
m2 = df['Distance'].gt(55)
# filter
df[m1|m2]
For the given input, the above code produces the following dataframe.
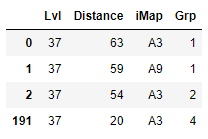
CodePudding user response:
You can reindex m1 to make it conform to df, like so
m1 = df[(df["Distance"]<55)].groupby('Grp').cumcount().eq(0).reindex(df.index, fill_values=False)