I am trying to send data to pySpark but it is giving me this error: ERROR MicroBatchExecution: Query [id = d3a1ed30-d223-4da4-9052-189b103afca8, runId = 70bfaa84-15c9-4c8b-9058-0f9a04ee4dd0] terminated with error java.lang.UnsatisfiedLinkError: 'boolean org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(java.lang.String, int)'
Producer
import tweepy
import json
import time
from kafka import KafkaProducer
import twitterauth as auth
import utils
producer = KafkaProducer(bootstrap_servers=["localhost:9092"], value_serializer=utils.json_serializer)
class twitterStream(tweepy.StreamingClient):
def on_connect(self):
print("Twitter Client Connected")
def on_tweet(self, raw_data):
if raw_data.referenced_tweets == None:
producer.send(topic="registered_user", value=raw_data.text)
print("Producer Running")
def on_error(self):
self.disconnect()
def adding_rules(self, keywords):
for terms in keywords:
self.add_rules(tweepy.StreamRule(terms))
if __name__ == "__main__":
stream = twitterStream(bearer_token=auth.bearer_token)
stream_terms = ['bitcoin','luna','etherum']
stream.adding_rules(stream_terms)
stream.filter(tweet_fields=['referenced_tweets'])
pySpark
from pyspark.sql import SparkSession
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import findspark
import json
import os
os.environ['PYSPARK_SUBMIT_ARGS'] = f'--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.3.0 pyspark-shell'
if __name__ == "__main__":
findspark.init()
# spark = SparkSession.builder.appName("Kafka Pyspark Streaming Learning").master("local[*]").getOrCreate()
sc = SparkSession.builder.master("local[*]") \
.appName('SparkByExamples.com') \
.getOrCreate()
df = sc \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("startingoffsets","latest") \
.option("subscribe", "registered_user") \
.load()
query = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
query = df.writeStream.format("console").start()
import time
time.sleep(10) # sleep 10 seconds
query.stop()
Hadoop Version: 3.3.0
Spark and PySpark version: 3.3.0
Scala Version: 2.12.15
I have tried everything for the last 8 hours still no luck. Could anyone help?
StackTrace:
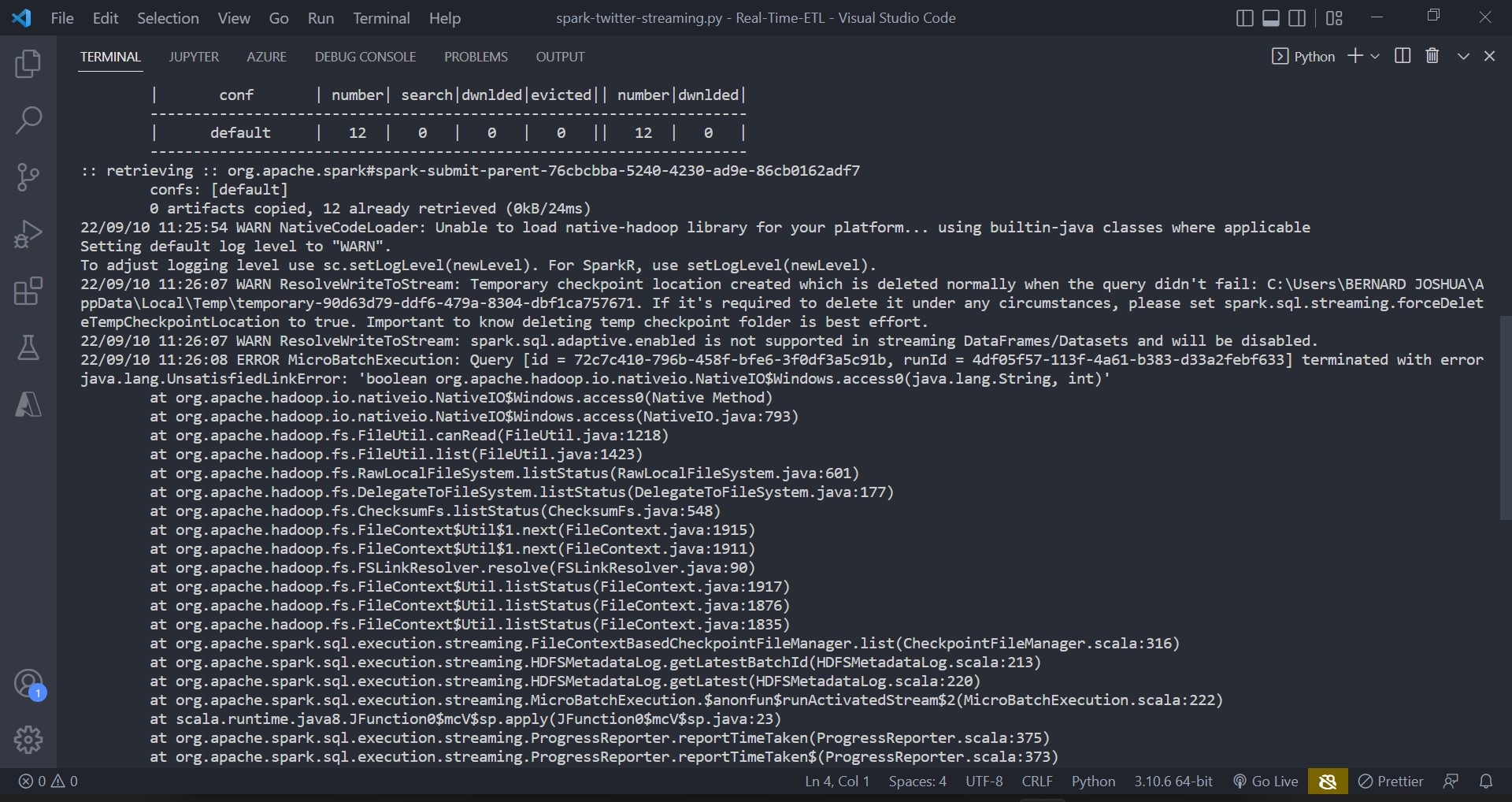
When I run df.printSchema() there is no error and this is the output:
CodePudding user response:
you need to use different name for holding the converted fields as the Dataframe is immutable , your initial dataframe is named df and it has certain schema, when you are casting the fields to string you need to have a seperate name.
castDf = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
query = castDf .writeStream...