I have multi-level data. The group level is individual persons, which are designated by id. The variable index indicates different time points. Is there a way to make a separate scatterplot (x vs. y) for each individual, all displayed in the same output, and ordered based on a third variable (z)? If so, can color then be added to indicate degree of third variable (z)? Data below, Thanks.
> dput(dat1.1)
structure(list(id = c(2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L,
2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L,
4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L,
4L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L,
5L, 5L, 5L, 5L, 5L, 5L), index = c(1L, 2L, 3L, 4L, 5L, 6L, 7L,
8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L,
1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L,
15L, 16L, 17L, 18L, 19L, 20L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L,
9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 1L,
2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L,
16L, 17L, 18L, 19L, 20L), x = c(7.443917, 7.520429, 7.446833,
8.07893, 8.534033, 8.263931, 7.598647, 6.902987, 7.672617, 7.739256,
7.591341, 8.101125, 7.811751, 6.596834, 6.637652, 8.467165, 7.835399,
6.500149, 7.083198, 7.531798, 6.110208, 6.368534, 5.26318, 6.735778,
5.580152, 5.460161, 5.844303, 6.258181, 7.191627, 5.105033, 6.760193,
5.857215, 5.866264, 6.769086, 6.547294, 5.623804, 4.675815, 6.153901,
6.040519, 6.236045, 8.216397, 6.097841, 5.491311, 5.831432, 6.297337,
6.655688, 5.553445, 6.37449, 6.271961, 6.959645, 7.080341, 6.46092,
6.476955, 7.221111, 6.219023, NA, NA, NA, NA, NA, 8.21752, 7.589581,
8.363739, 8.849697, 7.78645, 7.494006, 7.827766, 9.11352, 7.80884,
6.701855, 6.259061, 5.523358, 6.186617, 6.548538, 6.6937, 7.213297,
5.243428, 7.510827, 7.054297, 7.603241), y = c(106L, 114L, 50L,
50L, 56L, 46L, 50L, 52L, 114L, 50L, 56L, 26L, 48L, 52L, 48L,
54L, 54L, 56L, 52L, 50L, 84L, 86L, 88L, 86L, 82L, 84L, 88L, 84L,
86L, 84L, 86L, 86L, 84L, 84L, 88L, 88L, 88L, 84L, 86L, 120L,
106L, 168L, 116L, 56L, 108L, 68L, 68L, 70L, 74L, 76L, 76L, 76L,
72L, 70L, 118L, NA, NA, NA, NA, NA, 60L, 62L, 52L, 90L, 50L,
50L, 54L, 56L, 52L, 30L, 78L, 30L, 52L, 54L, 52L, 80L, 86L, 46L,
54L, 84L), z = c(33L, 33L, 33L, 33L, 33L, 33L, 33L, 33L, 33L,
33L, 33L, 33L, 33L, 33L, 33L, 33L, 33L, 33L, 33L, 33L, 54L, 54L,
54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L, 54L,
54L, 54L, 54L, 54L, 54L, 56L, 56L, 56L, 56L, 56L, 56L, 56L, 56L,
56L, 56L, 56L, 56L, 56L, 56L, 56L, 56L, 56L, 56L, 56L, 56L, 50L,
50L, 50L, 50L, 50L, 50L, 50L, 50L, 50L, 50L, 50L, 50L, 50L, 50L,
50L, 50L, 50L, 50L, 50L, 50L)), class = "data.frame", row.names = c(NA,
-80L))
CodePudding user response:
Does this come close to giving you what you want?
library(tidyverse)
d %>%
group_by(id) %>%
mutate(z=as.factor(z)) %>%
group_map(
function(.x, .y) {
.x %>%
ggplot()
geom_point(aes(x=x, y=y, colour=z))
facet_wrap(vars(z))
scale_colour_manual(drop=FALSE, values=d %>% distinct(z) %>% pull(z))
labs(title=.x$id[1])
},
.keep=TRUE
)
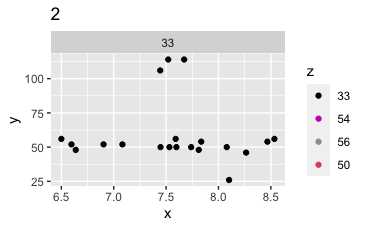
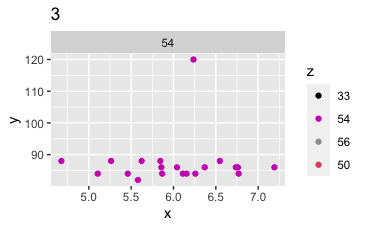
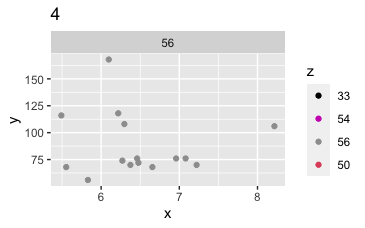
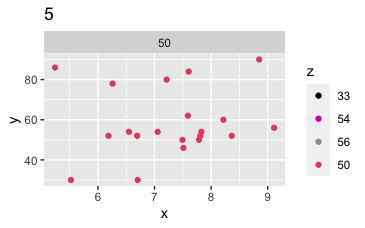
Points to note:
group_mapapplies a function to each group of a grouped data frame..xrefers to the data in the current group,.yis a one row tibble defining the group..keeprequests that the grouping variables are kept in.x.drop=FALSEin the call toscale_colour_manual()ensures that unused factor levels are retained in the legend (and hence different levels ofzare distinguishable between plots).