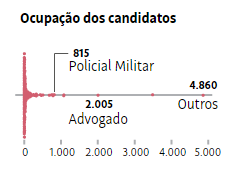
I've got a continuous variable where most observations are concentrated at one end of the spectrum. I'd like to display this in a graphic somewhat like this:
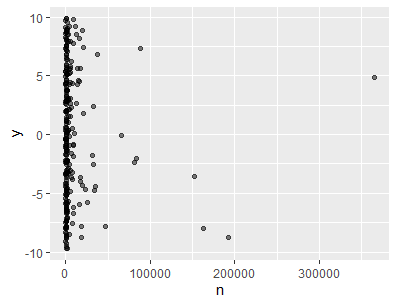
I tried it with position_jitter:
ver_ocupacoes |>
ggplot(mapping = aes(x = n, y = 0))
geom_point(alpha = 0.5, position = position_jitter(width = 0, height = 10, seed = 1))
And obtained this:
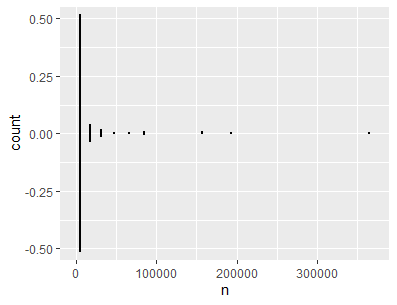
Also tried making a geom_dotplot instead:
ver_ocupacoes |>
ggplot(mapping = aes(x = n))
geom_dotplot(stackdir = "center",
stackratio = 0.5,
dotsize = 0.2,
method="dotdensity",
stackgroups = T,
binpositions="all")
And this was the result:
So neither one is quite what I want. Any ideas on how to jitter the points around a central axis like in the first example?
CodePudding user response:
Using geom_dotplot, you can use position_jitter with height = 0 and having the width approximately equal to the binwidth. Setting the binwidth to be a bit narrower will also help from the look of things.
ver_ocupacoes |>
ggplot(mapping = aes(x = n))
geom_hline(yintercept = 0)
geom_dotplot(stackdir = "center",
stackratio = 0.5,
dotsize = 1,
method ="dotdensity",
stackgroups = TRUE,
binpositions = "all",
binwidth = 5000,
position = position_jitter(width = 5000, height = 0),
color = 'red4', fill = 'red')
scale_x_continuous(labels = scales::comma)
theme_minimal(base_size = 20)
theme(axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
axis.title.y = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.y = element_blank())
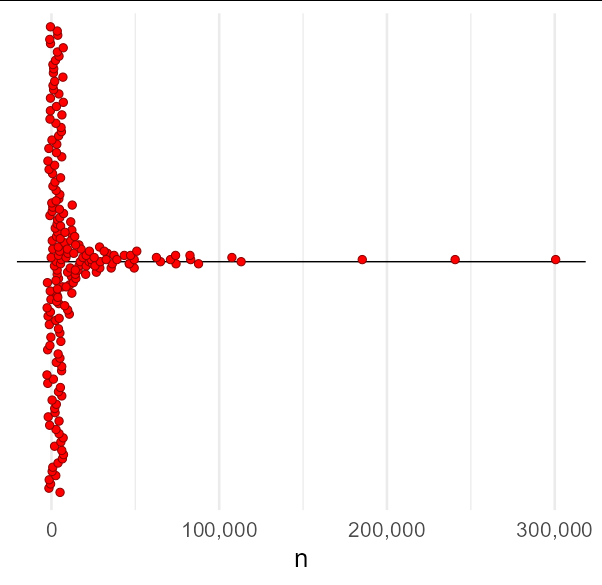
Data used
Obviously, we don't have your data, but the following appears to be a reasonable approximation and was used in the above example:
set.seed(1)
ver_ocupacoes <- data.frame(n = 1e5 * rexp(200, 2)^2.5/3)