I have a sales data table with cust_ids and their transaction dates.
I want to create a table that stores, for every customer, their cust_id, their last purchased date (on the basis of transaction dates) and the count of times they have purchased.
I wrote this code:
SELECT
cust_xref_id, txn_ts,
DENSE_RANK() OVER (PARTITION BY cust_xref_id ORDER BY CAST(txn_ts as timestamp) DESC) AS rank,
COUNT(txn_ts)
FROM
sales_data_table
But I understand that the above code would give an output like this (attached example picture)
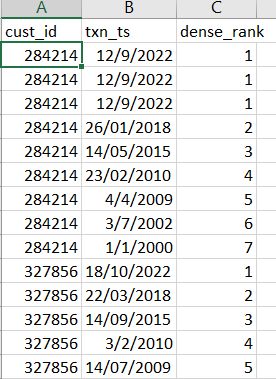
How do I modify the code to get an output like :

I am a beginner in SQL queries and would really appreciate any help! :)
CodePudding user response:
This would be an aggregation query which changes the table key from (customer_id, date) to (customer_id)
SELECT
cust_xref_id,
MAX(txn_ts) as last_purchase_date,
COUNT(txn_ts) as count_purchase_dates
FROM
sales_data_table
GROUP BY
cust_xref_id
CodePudding user response:
You are looking for last purchase date and count of distinct transaction dates ( like if a person buys twice, it should be considered as one single time). Although you mentioned you want count of dates but sample data shows you want count of distinct dates - customer 284214 transacted 9 times but distinct will give you 7.
So, here is the SQL you can use to get your result.
SELECT
cust_xref_id,
MAX(txn_ts) as last_purchase_date,
COUNT(distinct txn_ts) as count_purchase_dates -- Pls note distinct will count distinct dates
FROM sales_data_table
GROUP BY 1