I got data as in image 1.
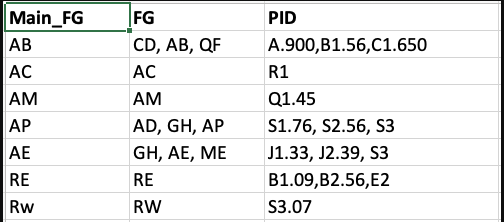
By using for loop in Python Pandas, I have splitted FG and PID columns as in image 2.
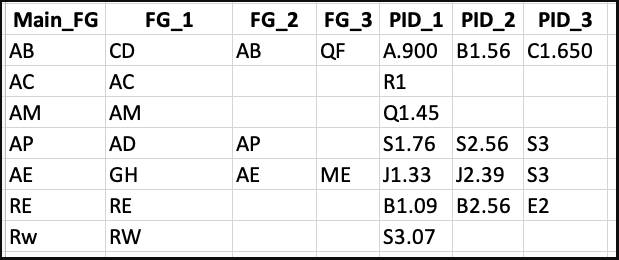
Based on the condition, I want the output as picture 3:
if Main_FG == FG_1, value will be from PID_1
if Main_FG == FG_2, value will be from PID_2
if Main_FG == FG_3, value will be from PID_3
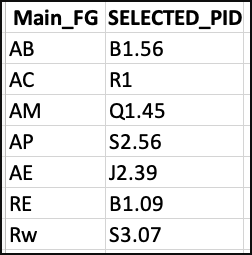
I have tried using for loop but does not help.
What would be the effective way to do that in Python? Please note that, the number of FG_1, FG_xxxxx, varies therefore, I need code to be dynamic and I am unable to do by using np.select.
CodePudding user response:
My approach is to define an external function to select the relevant PID
import pandas as pd
df = pd.DataFrame({'Main_FG': ['AB', 'AC', 'AM', 'AP', 'AE', 'RE', 'rw'],
'FG': ['CD, AB,QF', 'AC', 'AM', 'AD, GH,AP', 'GH, ae, ME', 'RE', 'RW'],
'PID': ['A.900,B1.56,C1.650', 'R1', 'Q1.45', 'S1.76,S2,56,S3', 'J1.33,J2.39,S3', 'B1.09, B2.56, E2', 'S3.07'] })
print(df)
Main_FG FG PID
0 AB CD, AB,QF A.900,B1.56,C1.650
1 AC AC R1
2 AM AM Q1.45
3 AP AD, GH,AP S1.76,S2,56,S3 #note the whitespaces between commas
4 AE GH, ae, ME J1.33,J2.39,S3 #note the lowercase
5 RE RE B1.09, B2.56, E2 #note the whitespaces between commas
6 rw RW S3.07 #note the lowercase
The function also takes care of 2 data cleaning steps:
(1) to compare based on lowercase,
(2) to split on comma but also to remove whitespaces
def select_pid(row):
idx = [e.strip().lower() for e in row['FG'].split(',')].index(row['Main_FG'].lower())
return [e.strip() for e in row['PID'].split(',')][idx]
df['SELECTED_PID'] = df.apply(lambda row: select_pid(row), axis=1)
print(df)
Main_FG FG PID SELECTED_PID
0 AB CD, AB,QF A.900,B1.56,C1.650 B1.56
1 AC AC R1 R1
2 AM AM Q1.45 Q1.45
3 AP AD, GH,AP S1.76,S2,56,S3 56
4 AE GH, ae, ME J1.33,J2.39,S3 J2.39
5 RE RE B1.09, B2.56, E2 B1.09
6 rw RW S3.07 S3.07
CodePudding user response:
Using a dummy example as yours is not reproducible.
You can use a list comprehension to loop over the key/values as a dictionary:
df['selected_PID'] = [dict(zip(k,v)).get(ref)
for ref,k,v in zip(df['main_FG'].str.upper(),
df['FG'].str.split(','),
df['PID'].str.split(','))]
NB. If you want to drop the columns, use df.pop('FG').str.split(',') in place of df['FG'].str.split(',') (same for PID).
Alternative with explode:
(df.assign(FG=df['FG'].str.split(','),
PID=df['PID'].str.split(',')
)
.explode(['FG', 'PID'])
.loc[lambda x: x['main_FG'].eq(x['FG'])]
.rename(columns={'PID': 'selected_PID'})
.drop(columns='FG')
)
output:
main_FG FG PID selected_PID
0 B A,B,C U,V,W V
1 E D,E X,Y Y
2 F F Z Z
used input:
main_FG FG PID
0 B A,B,C U,V,W
1 E D,E X,Y
2 F F Z
CodePudding user response:
You can use something like that:
from pandas import DataFrame, concat
df=DataFrame(data={'Main_FG': ['AB', 'AC', 'AM', 'AP', 'AE', 'RE', 'Rw'], 'FG_1': ['CD', 'AC', 'AM', 'AD', 'GH', 'RE', 'RW'], 'FG_2': ['AB', None, None, 'AP', 'AE', None, None], 'FG_3': ['QF', None, None, None, 'ME', None, None], 'PID_1': ['A.900', 'R1', 'Q1.45', 'S1.76', 'J1.33', 'B1.09', 'S3.07'], 'PID_2': ['B1.56', None, None, 'S2.56', 'J2.39', 'B2.56', None], 'PID_3': ['C1.650', None, None, 'S3', 'S3', 'E2', None]})
fg_cols = [col for col in df.columns if col.startswith('FG_')]
pid_cols = [col for col in df.columns if col.startswith('PID_')]
assert len(fg_cols) == len(pid_cols)
df_list = []
for i, fg_col in enumerate(fg_cols):
df_list.append(df[df['Main_FG'] == df[fg_col]][['Main_FG', pid_cols[i]]].rename(columns={pid_cols[i]: 'SELECTED_PID'}))
result_df = concat(df_list)
Main_FG SELECTED_PID
1 AC R1
2 AM Q1.45
5 RE B1.09
0 AB B1.56
3 AP S2.56
4 AE J2.39
You could sort the Main_FG column if you like.
CodePudding user response:
I am going from situation 2 to situation 3:
You can split your dataframe into two subdataframes. df1 containing FG_... and df2 containing PID_... columns. Create a mask using Main_FG and df1 and apply this on df2.
df = pd.DataFrame([
['AB', 'CD', 'AB', 'QF', 'A.900', 'B1.56', 'C1.650'],
['AC', 'AC', '', '', 'R1', '', ''],
['AM', 'AM', '', '', 'Q1.45', '', ''],
['AP', 'AD', 'GH', 'AP' , 'S1.76', 'S2.56', 'S3']],
columns=['Main_FG', 'FG_1', 'FG_2', 'FG_3', 'PID_1', 'PID_2', 'PID_3'])
n = len(df) // 2 1
df1 = df.iloc[:, 1:n]
df2 = df.iloc[:, n:]
mask = df1.eq(df.Main_FG, axis='rows')
mask[mask == 0] = np.nan
df['SELECTED_PID'] = (df2.values * mask).bfill(axis=1).iloc[:, 0]
df3 = df[['Main_FG', 'SELECTED_PID']]
Output df3:
Main_FG SELECTED_PID
0 AB B1.56
1 AC R1
2 AM Q1.45
3 AP S3
CodePudding user response:
It looks like problem described may be solved with a sequence of str.split
df['FG'].str.split(',')
df['PID'].str.split(',')
and explode method
df.explode(['FG', 'PID'])
Thus, you may arrive at the flattened dataframe